









We will be building solutions to common problems, which use several different database sources. To provide real-life examples, we will work through actual problems using different databases and SSIS to solve several common problems. We will do this by deliberately using different database types to work in a collaborative environment.
Editor’s Note: This article is excerpted from chapter 4 of Extract, Transform, and Load with SQL Server Integration Services--with Microsoft SQL Server, Oracle, and IBM DB2, by Thomas Snyder and Vedish Shah.
In Figure 4.1, you can see that we will be using the IBM DB2 database as our source system of record (SSoR or SOR). Database communications will be made to the SQL Server database using Web services, XML, and database-to-database operations. We will also be creating Excel spreadsheets from our database and sending extract, transform, and load (ETL) updates to our Oracle data warehouse.
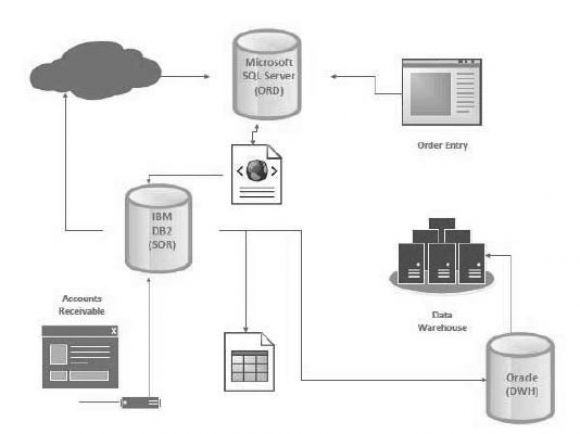
Figure 4.1: Base project diagram
We will be using a fictitious company, Fictitious Brewing Company, which distributes multiple premium beverage products. This company will take orders for members that distribute multiple products. The customers will be able to place orders online, and the website will maintain minimal customer information. And finally, our data warehouse will be updated with data from all our data sources.
We will start by building the database. You could simply create the databases and deploy the Data Definition Language (DDL) and Data Markup Language (DML) in the code. You can download all the code for the examples in the book at http://www.code-gorilla.com/Home/DatabaseAgnosticSSIS2016.
Getting the Most Benefit from This Series
This series will follow the project diagram in Figure 4.1, but you don’t need to tie yourself to the technical implementations used in the book. You may have a system with two IBM servers and an Oracle database, or three Microsoft servers, or maybe even DB2 with MySQL and PostgreSQL.
Table 4.1 shows the purpose of the tables in the book’s examples, which is illustrated in the naming conventions.
|
Table 4.1: Tables’ naming conventions and purposes |
|
|
Naming Convention |
Architecture Purpose |
|
SOR |
System of record |
|
ORD |
Order entry |
|
DWH |
Data warehouse |
Based on the databases that you are using within your environment, you may or may not be using the databases we are using with the examples in this book. That won’t be a problem: you can simply create the tables and seed the data in whatever database you are using. The only differences between your environment and the examples will reside in the data sources; everything else will be the same. The rest of the book will walk through applications that are decoupled from the databases, and you will follow along almost verbatim. Yay for database-agnostic development!
Some of you reading this may already be familiar with all three of the technologies that we will be reviewing in our examples: SQL Server, DB2, and Oracle. Other readers may be more familiar with other databases, such as MySQL or PostgreSQL, and want to learn more or walk through the examples to gain experience in other databases besides those covered in this book.
To address the needs of readers using other databases, we have written detailed instructions on how to deploy the initial DDL and DML code on each of the database servers. If you’re already familiar with these processes, you could skip most of this chapter and simply upload the source code to your intended target servers.
System of Record Database
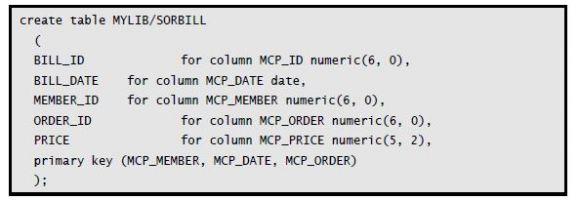
Once you upload the code on your IBM i, you can build the tables using the following command:

You need to replace MYLIB and MYSRC with the library and source locations to which you’ve uploaded. The MYMBR value will be replaced with the source member name—for example, MCPMEMBER, MCPBILL, and so on.
The Accounts Receivable database will reside on the IBM i in the DB2 database and will be our SOR for the members, products, and billing, so it makes sense to start here. Figure 4.2 shows the entity relationship diagram (ERD) for the database.
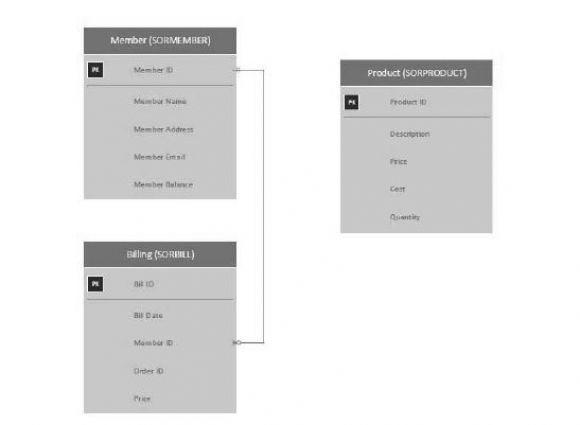
Figure 4.2: IBM DB2 crow’s foot SOR ERD diagram
With the intention of writing standardized code that is similar in multiple database environments, we will be setting up our databases in SQL Server using as little proprietary database syntax as possible.
Please keep in mind that SSIS will be working with multiple databases throughout this book, so you could just as easily choose another database as your SOR and port the tables into the database of your choice with minimal effort. Once we complete the creation of the databases and set up our data sources, you could be pulling any data from any database—which is where the fun comes in.
Member Table (SORMEMBER)
The member table in the DB2 database is the system of record for the members. This table contains the member ID, name, address, and balance. Whenever the billing process runs, the balance is updated on the member table. Any time the member is updated, it will be done in the MCPMEMBER table and pushed out to the external databases.

Product Table (SORPRODUCT)
The product table will be a simple list of products that members can purchase through orders. The products are intended to be maintained in the DB2 database and pushed out to the external databases.
We have deliberately kept the database simplistic; otherwise our product file would be more complicated and include other crucial information such as dates when prices may change, for example.

Billing Table (SORBILL)
The billing table will be our final stop in the Accounts Receivable database. This table will be used primarily by the data warehouse for sales analysis.
Deploying the Code
Because we make no assumptions about what database you’re familiar with, we will walk through the details of getting code into each of your databases.
FTP Source Code Upload
Uploading the source code to your IBM i server, you could use FTP from your local machine to your IBM i, as follows:

RUNSQLSTM to Execute SQL
Once you upload the code on your IBM i, you can build the tables using the following command:
![]()
Figure 4.3 shows the members in our database file, QDDSSRC in library MCPLIB.

Figure 4.3: IBM i DB2 RUNSQLSTM to execute SQL
You can review the execution of the SQL statement by looking at your spooled files; to do so, execute the following command:
![]()
If you place a 5 in the Opt column (Figure 4.4), you can view your success status. If you have any failures, you can review those in the spooled file as well.

Figure 4.4: Using the IBM i WRKSPLF command to review SQL execution
You can review the execution of the SQL statement by looking at your spool files; to do so, execute the following command:
![]()
Of course, there is always more than one way to do things. DSPFFD (Display File Field Description) is one of the many ways you could review your table layout in IBM i DB2, as shown in Figure 4.5.
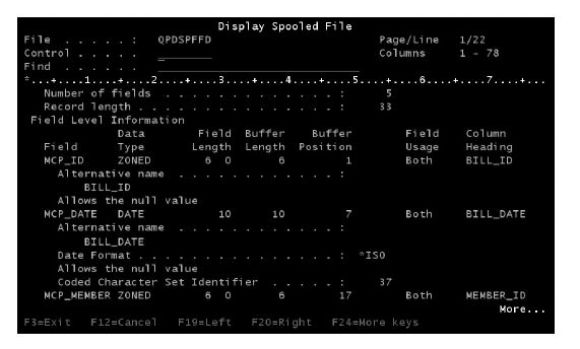
Figure 4.5: Using IBM i DB2 DSPFFD to review database table attributes
Next time: Database Setup: SQL Server Database. Can't wait? Pick up your copy of Tom's book, Extract, Transform, and Load with SQL Server Integration Services at the MC Press Bookstore Today!

Thomas Snyder has a diverse spectrum of programming experience encompassing IBM technologies, open source, Apple, and Microsoft and using these technologies with applications on the server, on the web, or on mobile devices.
Tom has more than 20 years' experience as a software developer in various environments, primarily in RPG, Java, C#, and PHP. He holds certifications in Java from Sun and PHP from Zend. Prior to software development, Tom worked as a hardware engineer at Intel. He is a proud United States Naval Veteran Submariner who served aboard the USS Whale SSN638 submarine.
Tom is the bestselling author of Advanced, Integrated RPG, which covers the latest programming techniques for RPG ILE and Java to use open-source technologies. His latest book, co-written with Vedish Shah, is Extract, Transform, and Load with SQL Server Integration Services.
Originally from and currently residing in Scranton, Pennsylvania, Tom is currently involved in a mobile application startup company, JoltRabbit LLC.
MC Press books written by Thomas Snyder available now on the MC Press Bookstore.
 |
Advanced, Integrated RPG See how to take advantage of the latest technologies from within existing RPG applications. List Price $79.95 Now On Sale
|
|
 |
Extract, Transform, and Load with SQL Server Integration Services Learn how to implement Microsoft’s SQL Server Integration Services for business applications. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online