









Access control is the core of the identity and access management task.
Editor’s note: This chapter is excerpted from chapter 4 of Identity Management: A Business Perspective.
Once we have correctly provisioned user data into the enterprise’s identity service, we can leverage it for access control. This leads us into the fascinating world of authentication and authorization.
Access Control Technology
Authentication and authorization refer to access control technologies. They allow us to manage who can get access to our computer systems, computer programs, and protected resources.
The line between the two functions is fuzzy, so we will start with the two ends of the authentication-authorization spectrum, shown in Figure 4.1.

Figure 4.1: Access control spectrum
Authentication
Authentication is the act of confirming that a user is who they purport to be before granting them access to corporate resources. There are various ways to achieve this, but it usually entails a lookup on a directory service to determine the user’s authority to access the requested service. A common use case is a network login process whereby a user enters their account name and password, the system then checks the directory service to see if the user has an active account and, if they do, provides access to the requested resource. In a Windows environment, once “logged in,” a user will be granted access to any Windows resource on the network to which they are permitted access without having to “authenticate” individually for each requirement, provided Windows authentication has been enabled.
The term authentication is also used to describe access to a computer system— that is, system administrators “authenticate” to a server. This gives them access to operating system functions and the ability to manage the server.
Sometimes the term is used to describe the logon to an application, although this is now getting closer to “authorization.” For instance, a user will sometimes be requested to “authenticate” to SharePoint, though in effect, the system is determining the user’s access to one or more team sites within SharePoint. Thus, a more accurate description would be that the user is “authorized” to SharePoint.
Authentication Levels
It is important to understand levels of authentication. There is a vast difference between a Google ID or Facebook login and a secure corporate login via the company’s identity management environment. The level of authentication will be determined by a risk analysis that evaluates “what can go wrong” if someone is inappropriately given access to an application.
The US National Institute of Standards and Technology (NIST)1 provides guidance on the determination of the authentication mechanism for a desired level of assurance. A four-level model has been used for the past few years, but since most jurisdictions’ privacy regulations mandate that anonymous or pseudonymous transactions must be supported, a five-level model is recommended, as shown in Figure 4.2.

Figure 4.2: Levels of authentication
As the level of risk increases, the authentication strength must be increased.
Level 0 is for anonymous transactions where it is not necessary to identify the user (e.g., the purchase of theatre tickets). It might be necessary to collect a name for fulfillment of the transaction, but the customer should be free to choose a pseudonym if they want to.
Level 1 is for low-assurance logins. Many public access systems are at level 1. They access information and may require a contact, but there is no sensitive information to be accessed by the user. A basic username and password are satisfactory.
Level 2 is still for low-assurance logins but typically for corporate applications. Since there is little sensitive information to be accessed by the user, a usernameand password will be required, and the company will typically impose a password policy that enforces a password of sufficient strength.
Level 3 is for medium-assurance applications where the user might be exposed to intellectual property of the organization or be able to access protected resources. In this instance, a higher-level authentication will be required, possibly protected by a biometric login or a digital certificate.
Level 4 is for high-assurance environments whereby significant damage could result if an incorrect authentication occurred. Industrial computer systems or military environments fit into this category. Public key infrastructure (PKI) or multi-factor authentication is appropriate.
Connecting a person’s identity-defining attributes and the person him or herself is the identity proofing task. This is typically a non-trivial task depending of the level of registration required. For high-security environments at level 3, a substantial registration process will be required because the issuance of a certificate should not be made lightly if the certificate will be used to access sensitive, protected information. On the other hand, if it’s simply to pay vehicle license fees, for example, a lower proofing level is satisfactory. Possibly this task could be outsourced to a public identity service by accepting social logins.
The steps then are:
- User submits application for
- Uniqueness is verified, and proofing documentation checks are
- Identity-proofing documents are
- An identity assurance level is
Levels of Assurance
Determining the level of assurance involves a risk management approach based on an assessment of what could go wrong if a person accesses the target application fraudulently. In the event that serious consequences may occur, a high level of assurance should be assigned to the application. If consequences are slight or of no consequence, there’s no point in engaging in a robust authentication process.
A typical evaluation process will be based on a four-level evaluation:
|
Low |
Little confidence in the accuracy or legitimacy of a claimed identity
Appropriate for transactions with minimal consequences to the organization or community from registration of a fraudulent identity |
|
Medium |
Some confidence in the claimed identity
Appropriate for transactions where there may be low-level consequences if someone with a fraudulent identity is registered and accesses a service to which they are not eligible. Some minor consequences to the community may occur. |
|
High |
High confidence in the claimed identity
Appropriate for transactions in which serious consequences could result from a fraudulent registration, such as inappropriate access to sensitive information or protected computer systems that could cause harm to the community |
|
Very High |
Very high confidence in the claimed identity
Appropriate for transactions with very serious consequences associated with a fraudulent registration that has significant consequences to the community, such as the fraudulent issuance of a document commonly used as evidence of identity |
Authorization
Once a user is authenticated, authorization provides access to computer programs (applications) commensurate with the user’s authenticated identity. This typically involves a lookup of the user’s record in the identity repository to determine their access rights within the requested application. There are several ways to achieve this.
Coarse-grained authorization is often achieved via AD groups. A number of AD groups will be established for an application, and the requesting user’s AD group membership will determine the access they are granted in the application. For instance, if a user is in the Project Manager AD Group, the user will be authorized to the project management system as a manager. If a user is in one of the Project Team Member groups, he or she will be authorized to the appropriate project(s) at the user level.
Fine-grained authorization is completely different. It usually involves an authorization server that relies on a directory for attributes on users who request access to a protected resource, but it extends to a full dynamic attribute-based access control (ABAC) solution incorporating a decision point, one or more information points, and multiple enforcement points. The benefit that fine-grained authorization provides is the ability to establish centrally managed policies to provide governance over the authorization task.
This is a critical activity for any organization, but it becomes particularly important for a company with high-security requirements.
Access Control Types
Now it’s time to change tack and consider authentication and authorization from another viewpoint. There are basically two approaches to enabling access control: a role-based approach that is usually used in the authentication task, and attribute-based access control that is the core of an authorization approach.
Authentication based on AD groups is a type of role-based access control. Users are provisioned into specific AD groups based on the workgroup in which they work or the department they belong to. In this way, they get access to systems and applications based on their “role” within the organization.
In an attribute-based access control system, shown in Figure 4.3, access is granted based on user attributes that are compared against policies that control who should get access to an application. The policy decision point (PDP) compares attributes that have been provisioned against a user in the identity repository, as well as context attributes such as the time of day, to determine the level of access a user should receive in the requested application.
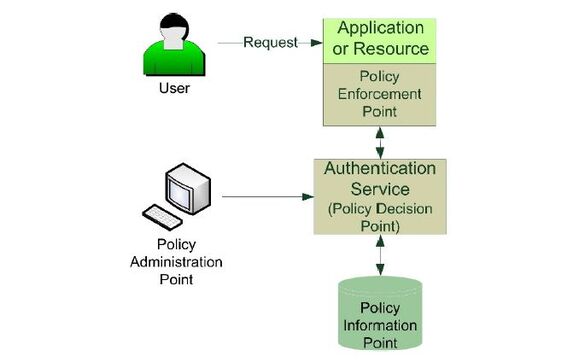
Figure 4.3: Attribute-based access control
Role-based Access Control
Role-based access control (RBAC) has served us well and remains a positive and efficient way in which to automate the granting of permissions to users, based on their roles in the organization. When a person joins an organization, their access to systems and protected resources in the organization should be commensurate with their role(s). Furthermore, when one or more of their roles change, their access to systems should change accordingly. For instance, if a person is a finance manager, they should have access to the financial management system at a manager level. If they then act as the chief finance officer (CFO) for two weeks while their manager is on vacation, they should be given access to the CEO meeting documentation for that period of time. If the manager is then transferred from Finance to HR, they should lose access to the Finance system and be given access to the HR system. This should happen automatically with human intervention limited to managing exceptions.
RBAC is therefore an efficient way to manage staff access to protected resources. RBAC becomes difficult, however, if there are too many roles. Over time, these lists become bloated and result in inherent risks to the organization. Often it is necessary for the organization to conduct a thorough assessment of the current assigned roles, which may lead to a consolidation and reduction of roles to those which are essential.

RBAC Example
Although there are many variants, all RBAC environments use a person’s role information to grant access to applications. Let’s look at an example, illustrated in Figure 4.4.
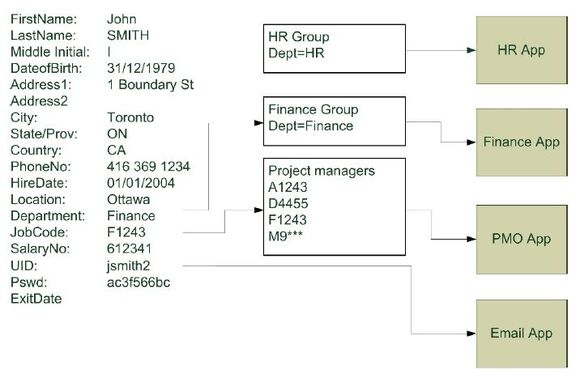
Figure 4.4: RBAC example
In Figure 4.4, John Smith is a Toronto-based staff member working in Ottawa. He gets access to the Finance application because he is in the Finance group. During provisioning, this group can be populated automatically from the Dept attribute in the organization’s directory. The application’s access control logic is configured to reference the appropriate groups when a user logs in.
In this instance, the project manager’s group is configured for JobCode F1243, so John also gets access to the Project Management Office (PMO) application. This application’s access control logic will perform a lookup on the corporate directory, when authenticating users, to retrieve the appropriate job code for the user in order to connect them to the application’s functionality at the appropriate level.
Finally, John gets provisioned into the email program, as do all staff. Note: John does not get access to the HR application because he’s not in the HR department. If he wants to access his HR record, he must contact someone in HR, unless the company has a self-service tool, with appropriate access control, to allow the user to access their record directly.
The Attribute Approach
In contrast to the RBAC example, attribute-based access control (ABAC) takes a very different approach to authorization. Access to protected resources is based on a user’s having specific attributes—for example, name, date of birth, hire date, address, phone number, job title. This allows a much more fine-grained access control approach that combines not only user attributes but other data, such as location (IP address or GPS) and time of day, in the access control decision. It allows unprecedented control of access to restricted resources based on fine- grained attributes evaluated at runtime. Rather than just using the role of a user to decide whether or not to grant them access to a system or protected resource, ABAC can combine multiple attributes to make a context-aware decision in regard to individual requests for access.
Privacy Considerations
A rules-based approach to access control can leverage identity attributes to incorporate privacy requirements such as:
- Data minimization, where only personal data that is required for the provision of the requested product and service should be collected by an organization. It is not permissible to collect data that “might be” useful at some point in the future.
- Ensuring that anonymity is preserved if a person’s identity is not needed for a It is only permissible to identity someone if doing so is required for the requested transaction.
- Restrictions on outsourcing personal data (e.g., several jurisdictions expressly prohibit personal data disclosure to a jurisdiction without similar privacy legislation)
- Enforcing use of personal data for only the express purpose for which it was collected and ensuring that any secondary purpose includes the collection of the individual’s consent
- Ensuring government identifiers are not used for indexing
- Ensuring identity data is periodically updated to maintain its currency or is If effort is not put into refreshing identity data on members of the public, in most jurisdictions it is illegal to keep this data.
ABAC holds significant promise for organizations that have a good identity management environment; it allows access to protected resources to be more fine-grained. That means that better overall security and improved data protection are achieved, and data governance is improved.
ABAC Example
There are various approaches to ABAC, but they all rely on a rich data store of attributes generally aggregated from multiple authoritative sources. The core principle is to adhere to a published policy that determines the attributes required to gain access to protected resources.
In the ABAC example shown in Figure 4.5, John will again get access to the finance application because he’s in the finance department, but only on a view basis because that’s all an F1** job code allows. He is also restricted to access during business hours. The access control system will allow him to access the PMO application but only the Ottawa projects.

Figure 4.5: ABAC example
While John can’t modify an HR system record, the use of ABAC supports a more fine-grained access to the application that allows him to view his own HR record. For HR staff, access can be segmented to roles; for example, if an HR person has a recruiting job function, they should get access to the recruiting subsystem; HR managers would get access as an administrator.
The benefits of an ABAC approach are significant:
- Access decisions are centrally managed via policies rather than by individual application managers. This means that they are consistent across the organization, and administered by business managers rather than controlled by IT personnel.
- Software development is simplified by the removal of access control logic and the incorporation of “policy enforcement point” code, which externalizes the access decision to a “policy decision point.”
- Decisions are made at runtime based on attributes that can be combined to form fine-grained decisions; changes in access status are immediately recognized when attributes are updated.
From a business viewpoint, this means a vastly reduced risk profile; access rights will be modified as soon as the source system reflects the change. No longer will “old permissions” stay in the system when an attribute changes or a staff member leaves the organization’s employ. Access rights are no longer based on access control lists that require manual intervention in order to be updated.
It also means lower costs: without manual intervention, there are no recurring costs for updating system access rights. Another benefit is that software development is less expensive because ABAC removes the cost of developing sophisticated access control logic from applications.
There are several considerations when moving to an attribute-based access control environment, and some challenges as well. First, a mature identity and access management environment is a prerequisite because ABAC requires a robust data model with predefined “authoritative sources” and efficient “source of truth” repositories for all attributes. Authentication is a mission-critical service; it must be highly available, and it cannot tolerate excessive network latency. This means that in some cases, a synchronization business model might be required whereby remote data stores are synchronized to a local directory or database.
Historical Note
It is useful to review the history of RBAC and ABAC.
Back in 1992, the US National Computer Security Conference issued a best practice document on RBAC, and in 1995 NIST issued an ITL bulletin indicating how RBAC should be implemented. The intent was to bring some commonality to the business processes associated with access control. These documents represent a seminal endorsement of the RBAC approach to access control.
In 2014 NIST issued SP-800 162 to provide best-practice guidelines for ABAC. The document provides a high-level view of ABAC and emphasizes the benefits associated with fine-grained access control. NIST has not endorsed any one ABAC protocol. While recognizing XACML as the most widely deployed protocol, NIST strongly supports what it calls Next Generation Access Control (NGAC) and has contributed to a functional architecture to support this approach, released as ANSI INCITS 499-2013.
APAM: An ABAC Implementation
ABAC has been with us for many years; it embodies a wide range of systems that control access to protected resources based on the attributes of the requesting party. As the field has developed, there are three characteristics that are most desirable in an ABAC system:
- It should externalize decision-making (i.e., not require applications to maintain their own access control logic).
- It should be adaptive (i.e., decisions are made in real time).
- It should be policy-based (i.e., access permissions should be determined based on evaluation of access control policies).
- It should be more than just control: business units become enabled to “manage” user’s access control.
Adaptive policy-based access management (APAM) is a better term to describe a system that embodies these characteristics. It’s adaptive because policies are evaluated at runtime, it’s policy-based, and it’s more than just access control: it’s access management.
Attribute-based systems have several advantages: First, decisions are externalized to dedicated infrastructure that performs the policy evaluation. Decisions are also more fine-grained: if a user is a department manager, an APAM system can also check a user’s department code and so decide, for instance, whether or not to give them access to the financial management system. It can check whether or not they are using their registered smartphone, and it can determine the time of day to make decisions that reduce the risk associated with an access request. Such systems are usually managed via a set of policies that allow business units to determine, for instance, whether or not they want to allow access from a smartphone, and if they do, to elevate the authorization level by using a two-factor mechanism.
The benefits are obvious: no longer are we dependent upon someone in IT to update an AD group, and more sophisticated decisions are possible. APAM systems are also real time. As soon as HR updates a person’s position, their permissions are modified. The very next access request will be evaluated against the same policy set, but the new attributes may return a different decision.
The Configuration
To exploit the potential of APAM, it is necessary to augment one’s IAM infrastructure to include a couple of additional items. Figure 4.6 shows a typical APAM configuration.
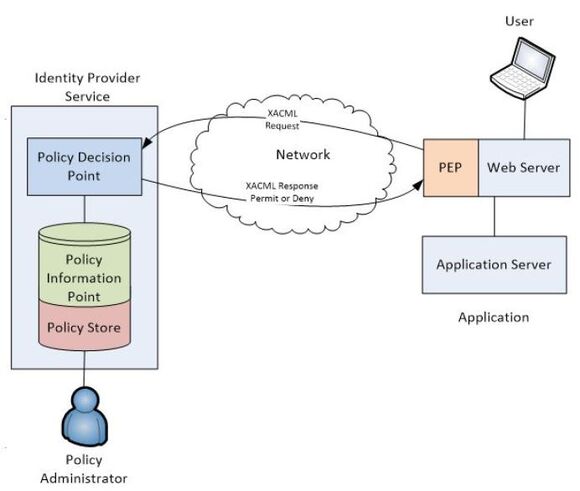
Figure 4.6: APAM configuration
The directory store migrates to an “information point,” which provides the necessary data for the decision point to render a permit or deny decision. These decisions are interpreted by the enforcement point, a piece of code that sits on the Web server and controls access to the application in question.
Next time: The Query-Response Language. Want to learn more now? Buy Graham's book today at the MC Press Bookstore.
Graham Williamson is an identity management consultant in Brisbane, Australia. He has 27 years of experience in the IT industry, with expertise in identity management, electronic directories, public key infrastructure, smart card technology, and enterprise architecture. He is a coauthor of Identity Management: A Primer and the author of Identity Management: A Business Perspective.
MC Press books written by Graham Williamson available now on the MC Press Bookstore.
 |
Identity Management: A Business Perspective Understand all facets of identity management and how to leverage identity data for access control. List Price $49.95 Now On Sale
|
|
 |
Identity Management: A Primer Get a comprehensive overview of the elements required for a properly planned identity environment. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online