









Journals and SQL are two of the most powerful features of DB2 for the IBM i; together they create an incredible tool to help manage your data access.
As IBM midrange programmers, we’ve long been familiar with journaling. It’s the way the IBM i tracks changes to the database. Journals can be used to recover or reverse changes. Journaling is the basis of commitment control for DB2. Journaling is the underpinning for many high-availability replication tools, both commercial and home-brewed. But to me, the best feature of journaling is the ability to see when a database gets changed. It’s invaluable for forensic application debugging, something I do on a regular basis. And while the built-in support for journaling on the IBM i is functional, it isn’t all that user-friendly. This article will show you how to make it a lot more accessible through SQL.
Journaling Basics
Without turning this into a Journaling 101 article, let me quickly outline the basics. When you journal a file, the journal keeps track of all I/O operations to that file. For record-based events (adds, changes, and deletes), the journal includes the actual record data from the file. So let’s update a journaled file and see what the changes look like. I updated a record in a file called PRODUCT; we’ll review the results. We can start with the simplest command, DSPJRN. With DSPJRN, we see these entries:
Opt Sequence Code Type Object Library Job Time
_ 11 R UB PRODUCT ADTSLAB MYJOB1 14:07:41
_ 12 R UP PRODUCT ADTSLAB MYJOB1 14:07:41
You can see the UB entry, which contains the data before the change, and UP, which shows the after image. You can configure the journaling on a file so that the before image is not captured, but these days I always include both. This way, you will also see the data that was in a record that was deleted. That’s a subject better dealt with in an article more geared toward journaling itself.
What’s the Problem?
I wouldn’t exactly call it a problem, but more of an unavoidable consequence of how journals work. Since a journal can be used for any number of files with any number of formats, the data isn’t stored in easily accessible fields; instead, the entire record is stored as a single character field. Let’s take a look at that. Here is the layout of the PRODUCT file:
Field Description Name Type Length Dec
Part number PARTNO A 5
Model MODEL A 5
Wholesale price PARTPRI P 7 2
Retail price PARTMSR P 7 2
Volume discount PARTDIS A 1
First ship date PARTSHIP L 10
And here is the record that I changed (in case you’re wondering, I used DBU, but it doesn’t matter; the journal will capture the change no matter how I do it):
Part number....... PARTNO 00562
Model.............. MODEL AR-13
Wholesale price.. PARTPRI 11.45 ß I changed this to 11.60
Retail price..... PARTMSR 13.00
Volume discount.. PARTDIS N
First ship date. PARTSHIP 1991-09-25
The file PRODUCT has six fields. Three are character fields, two are packed decimal, one is a date. If I journal this file, whenever a record-based event is recorded, the data is stored as a single field. Now, let’s take a look at the data in the journal entry. You can take option 5 to see the data. Let’s do that first on the UB (before image) and then on the UP (after image) entries.

Figure 1: The UB (before image)
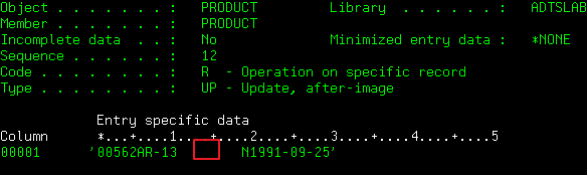
Figure 2: The UP (after image)
You can see that the two images are indeed different, but you can’t tell exactly how the value changed because it’s a packed field. You can see the data in hexadecimal format, but that has its own issues (for example, unless you’re really good with EBCDIC, it’s hard to tell what is in the character fields):

Figure 3: Data in hexadecimal format
All in all, trying to interpret the changes is difficult.
Analyzing Multiple Changes Using a Journal Extract File
Looking at the journal one entry at a time is sometimes useful, but far more often you’ll want to look at and analyze a range of data. The DSPJRN command allows you to extract journal entries to an output file. We’re not going to spend a lot of time on the options of DSPJRN, but here’s the command I use to dump the journal:
DSPJRN JRN(JRN) OBJ((PRODUCT *FILE)) ENTTYP(*RCD)
OUTPUT(*OUTFILE) OUTFILE(ADTSLAB/J_PRODUCT) OUTMBR(*FIRST *ADD)
This dumps the journal entries for the file PRODUCT to a file called J_PRODUCT. Now, I can look at those journal entries using any database tool, but I still have a problem:

Figure 4: The column labeled “Specific Data” is a single field that concatenates all the fields from the PRODUCT file
As you can see, the column labeled “Specific Data” is a single field that concatenates all the fields from the PRODUCT file, much like the DSPJRN display itself. Yes, you can look at it in hexadecimal, but it’s still very cumbersome, and selecting based on one of those fields is very difficult. So now it’s time to introduce the SQL commands that will make this task a lot easier.
Using SQL to Enhance the Extracted Data
The steps to making this data readable are simple:
- Create a table with the needed fields from the extract file, including the concatenated record data field.
- Create an empty table with all those fields except the last field and instead using the fields from the journaled file.
- Copy the data from file 1 to file 2, using the option FMTOPT(*NOCHK).
In the first step, I identify the fields I want from the journal extract file and create a table using SQL. Typically, I’ll include the journal code and entry type, the date and time, and the job and program that made the change. I’ll also include the record number. My SQL build statement for step 1 looks like this:
CREATE TABLE ADTSLAB/X_PRODUCT AS
(SELECT JOCODE, JOENTT, JODATE, JOTIME, JOJOB, JOUSER,
JONBR, JOPGM, JOCTRR, JOESD FROM J_PRODUCT)
WITH DATA
This creates a table called X_PRODUCT (X for extract). You’ll notice I include all the fields I want, ending with JOESD. I use WITH DATA so that the newly created table includes the journal entries. Next, I create an empty table that has the journal fields I want and the fields from the journaled file. That SQL statement looks very similar, but with a couple of important differences:
CREATE TABLE ADTSLAB/V_PRODUCT AS
(SELECT JOCODE, JOENTT, JODATE, JOTIME, JOJOB, JOUSER,
JONBR, JOPGM, JOCTRR, PRODUCT.*
FROM J_PRODUCT JOIN PRODUCT ON JOCODE = '')
WITH NO DATA
This creates an empty table V_PRODUCT (V for view). Notice that I include exactly the same fields from J_PRODUCT in exactly the same order, except for JOESD. Instead, I include all the fields from PRODUCT by using a JOIN, although the JOIN is really a dummy comparison. Finally, I specify WITH NO DATA. Now I have an empty file where in place of the single field named JOESD, I have all the fields from the PRODUCT file. The last step is just to copy the X_PRODUCT file to the V_PRODUCT file, using FMTOPT(*NOCHK) to tell DB2 to ignore any differences. The command is simple:
CPYF FROMFILE(X_PRODUCT) TOFILE(V_PRODUCT) MBROPT(*REPLACE) FMTOPT(*NOCHK)
If I look at the newly populated V_PRODUCT file, I get something usable:
![]()
Figure 5: Now we get something useful
This shows clearly that user ME changed the Wholesale price field on record 4 from 11.45 to 11.60. More importantly, I can now analyze the file. I can easily select on entries where, for instance, a record was added with a zero price. Even better, I can JOIN a before image to an after image to find cases where a price was increased, even checking to see if that increase was above a certain threshold. This takes the DB2 journal from base functionality to a powerful analysis tool.
Final Notes
I would be remiss to not mention that similar functionality is available in the TOOLS/400 command EXPJRNE, written by the amazing Thomas Raddatz 20 years ago without the benefit of the SQL tools I use today. I have used EXPJRNE on more projects than I can count, and it was the inspiration for me to research this SQL-based functionality. In a follow-up article, I plan to provide the framework for an even more powerful utility that will do all of this in a single SQLRPGLE program, but until then, please enjoy this concept; I hope it helps even a fraction as much as EXPJRNE helped me.

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online