








Understanding the Event Loop is critical to JavaScript development both in the browser and in Node.js.
In my day-to-day work, I switch between RPG and JavaScript development constantly. While I do not consider myself the ultimate authority on JavaScript, I do have a solid working knowledge of the language. There was a time when JavaScript was only used for browser manipulation at runtime, but with the rise of Node.js, which is now available on IBM i, JavaScript is becoming a major player for server-side development as well.
As RPG developers, we work, at least the majority of the time, in a very top-down, single-threaded model. When we start working with JavaScript, asynchronous code and callback functions can be very confusing. Our goal in this article is not to learn the JavaScript language. That would take an entire book! Instead, let’s examine what these things are, how they work, and how they relate to familiar IBM i concepts.
Asynchronous Code
JavaScript by itself is a very simple modular language. When running a script, it of course runs the code as written. It is inherently single-threaded, meaning it can run only one piece of code at a time. Like any other programming language, you can create functions that receive and return parameters, have scoped variables, and return values to allow the function to be nested inside a calculation or as a parameter of another function. This is no different from RPG. Obviously, the syntax is different, but RPG subprocedures can do all the things just mentioned.
The fun begins when we start calling functions provided by either the browser or Node.js that run asynchronously. Why would we want to do that? You would want something to run asynchronously for the same reasons you would want to submit a job on IBM i or write data to a data queue to be processed later. The idea is to get long-running processes out of the call stack. When a long-running process runs in JavaScript’s single-threaded call stack, it is called “blocking.” When this happens in the browser, the page seems to freeze. The page will not respond to the user’s interactions immediately, or worse, if the page has not finished loading, the browser can stop rendering until the blocking code finishes.
So, to prevent blocking, we run certain slow-running processes asynchronously, but how do we do that? Asynchronous functions are provided by the environment in which we are running. The JavaScript language is single-threaded, so it has no concept of running code asynchronously. This functionality is implemented using APIs provided by either the browser or Node.js environment. For simplicity, we will concentrate on JavaScript in the browser, but the concepts will carry over to Node.js as well. The two most common methods running code asynchronously are as follows:
setTimeout()
The setTimeout() function is used to delay the running of a function. It is available in all browsers and in the Node.js environment. You will find it used in JavaScript libraries and example code frequently, and it is very simple to use.
It accepts two parameters. The first is a callback function. This is the function that contains the code you would like to run asynchronously. You can pass a function name or even create an inline function, meaning you write the code within the parameter itself. Again, the focus of this article is not the syntax of writing a callback. There are plenty of online resources for that.
The second parameter is the amount of time to wait before putting the callback function on the queue. The time is in milliseconds. This does not guarantee that the callback will run in exactly the amount of time specified. Instead, it only ensures it will not run before that amount of time. We will discuss why shortly.
AJAX Requests
AJAX requests are used to retrieve resources from the web server asynchronously. This is important for creating smooth user interfaces in the browser. If the web server is slow returning data used in part of your application, you do not want block the call stack waiting for the response. If the server is having issues, the response may never come!
In the browser, the XMLHttpRequest object is used to implement AJAX requests. Setting it up is more complicated than using setTimeout(), but the primary steps are to define an instance of the XMLHttpRequest object, add a callback function to run when a response is received, set the URL and parameters to be used for the call, and send the request. Implementing an AJAX request is a topic for another day, so we will move on with our discussion.
XMLHttpRequest does not exist in Node.js by default, but it can be imported. However, the preferred method in Node.js would be to use the HTTP interface included in that environment. If you’re using a library or framework, it may have its own functions for making AJAX requests as well.
Callback Functions, the Call Stack, and the Callback Queue
The one thing that both methods above have in common is they use callback functions. Any API you call that uses a callback function will be run asynchronously. To fully understand the processing of asynchronous code, let’s examine the environment.
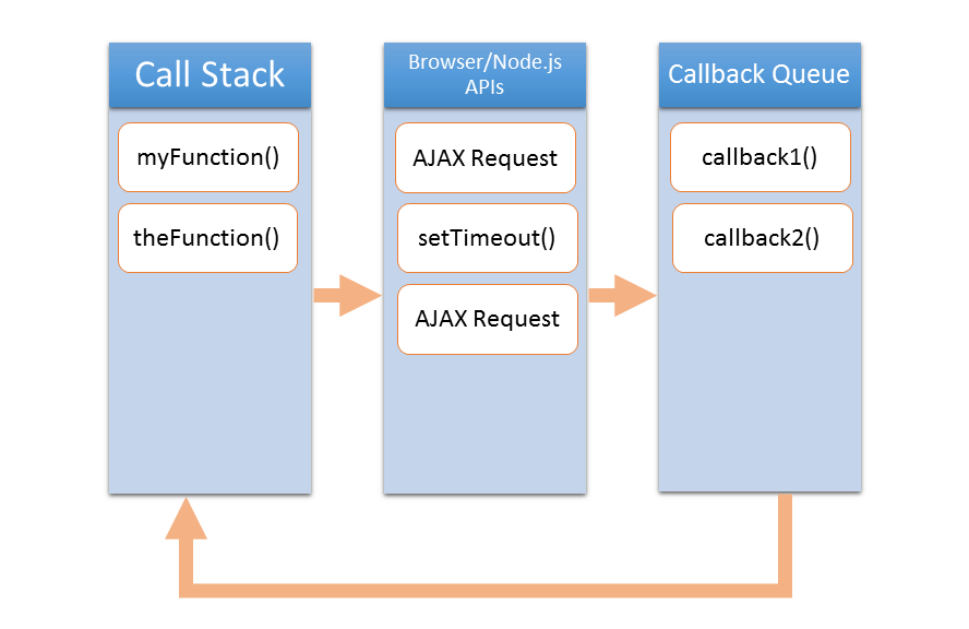
Figure 1: This image shows a simplified representation of the JavaScript environment.
As illustrated above, there are three areas where code can be running. The first is the Call Stack. The call stack is a part of the JavaScript language’s runtime. It is single-threaded, meaning that it can only process one thing at a time. This is very similar to the call stack of an IBM i job. The call stack will contain the current function running and all the parent functions. Because it is single-threaded, this is where blocking can happen.
The next area is where the browser or Node.js implement their APIs. This area is not single-threaded and allows us to implement asynchronous techniques. It is also important to note that his area is implemented outside of the JavaScript language itself. Think of this as jobs that have been submitted to batch on IBM i. We send the process here to run and then continue running our application. This is also where our browser events fire, such as onclick, onload, etc. Any code we have attached to a browser event either directly or using an event listener will be run as a callback as well.
The last area is the Callback Queue. This is a single-threaded queue where our callback functions are placed when our APIs are finished processing. In the case of setTimeout(), the browser just counts down from the time passed in on the second parameter. Once the timer reaches zero, the callback function is placed on the callback queue. For an AJAX request, when certain responses are received from the server, the callback function for that event is placed on the queue.
The callback queue could be thought of as being like an IBM i job queue with max active jobs set to 1. It is a list of functions waiting to run. What is slightly different about it is the Event Loop.
The event loop constantly monitors the call stack. Whenever the call stack is empty, it will take the next function on the callback queue and place it in the call stack to run. The key is that it will do this only when the call stack is empty. So, callback functions will run only when all currently running JavaScript code is completed. This is why the callback function on a setTimeout() may not run in the exact amount of time passed in. setTimeout() simply waits the specified amount of time to place the callback on the callback queue. If the call stack is busy, or other callback functions are already on the callback queue, the callback function must still wait to process. Therefore, you may often see JavaScript code like this:
setTimeout(myFunction(), 0);
At first glance, it would seem silly to do this instead of call the function immediately. What this does, however, is put the function at the back of the callback queue, ensuring that this code runs after all currently running code is complete in order to avoid blocking and ensure that all prerequisite code has completed.
There is an interesting tool called Loupe that can help visualize how all of this works. Just visit that page and open your browser’s development tools. Specifically, look at the console while running code in Loupe. This great visual tool can help you understand how all of this works. Philip Roberts, the author of Loupe, also has a half-hour talk he gave on Loupe and the Event Loop available on YouTube if you want to delve a bit deeper into the topic.
Final Thoughts
I hope this adds some clarity to how callbacks work in JavaScript. It is very common in my experience for RPG developers new to JavaScript to be confused by this topic.
This piece is a bit of a departure from previous topics, but I have been considering building more “JavaScript for RPG Developers” content. It may manifest as a series of articles. I am even considering writing a book on the topic. So I want some feedback from you. Is this type of content interesting or helpful? Do you want more on this topic? Should I dive deeper and author a book on the topic?
Please leave your thoughts in the comments. I would sincerely appreciate your input.

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online