









So this is all very awesome IMHO, and actually any programmer would love this stuff. Easy, fast, flexible. But we IBM i folks have a bunch of stuff already written and living in the “alternate universe” of IBM i (OS/400)—so, how do we get to that stuff?
Check out Part One of this excerpt series. And Parts Two, Three, Four and Five are here.
Editor's Note: This article is excerpted from chapter 10 of Open Source Starter Guide for IBM i Developers, by Pete Helgren.
System Access
There’s a toolkit for that! But first, let’s access the environment that Node.js lives in, and that is PASE. Getting to PASE is easy because it is the ocean we are swimming in. It is this easy:

Much of what Node.js does is asynchronous, so in this case we are running a synchronous process—we will wait, thank you very much, for the output rather than including a callback to return the output when it completes. So that is what require('child_process'). execSync is going to do: run a synchronous child process and return the output. That output comes in the form of a buffer of raw data, so we use the toString() method to get a string from the contents. Voilà! Our ls -l command returns the list of the files in the directory it is executed in. Easy.
Access to the IBM layer is a little more involved, but not much, because we already have libraries that wrap the XMLSERVICE routines, and if we need direct access to IBM i databases, we have libraries that can do that as well. The database access is a fairly straightforward process, one that may be familiar to you, so we’ll start there.
DB2 Database Access
As I mentioned before, you don’t have to slog through much here because the pioneers of Node.js and DB2 have gone before you. There is a library on your system (after installing 5733OPS) that is just waiting for you to use it. So let’s do it!


I tried to write this in a way that was generic and would output whatever table you decided to use in your SELECT statement. An additional idea that you could also implement here would be to output to a .csv file. But since we are, in most cases, going to be writing a Web app or something along those lines, the fact that the content is automagically formatted in JSON means that you’ll get back an object from your database call, which is actually perfect for the Web environment.
A quick walk through the code shows you how simple it all is. Our first require line pulls in everything we need for database access into an object called db. So that is a pretty sweet start. The next require line I threw together because you probably don’t want to hard-code credentials in your app. So I created a config.json file in the application’s folder where you can stuff the username and password for connections. But don’t stop there. The config.json file (it can be any name) can contain whatever you want: system name, database name, SQL settings, and so on.
The require('./config.json'); returns an object with the properties you defined in the file. (Hey! You are in objectland now, so a .json file is coming back as an object.) You reference the properties you defined using variable.property syntax. In my case, it is conf.password and conf.username. That file looks like this:

All standard JSON stuff! Next we start a try block, so that if we have any errors we can catch and display them. Within the try, we set a couple of properties and initialize the db object. Next we use the conn method, passing in connection parameters. Then we run the exec method, passing in the SELECT statement. We could have just as easily issued a CREATE TABLE, INSERT INTO, DROP TABLE, or any other SQL executable statement within that exec method. In that same method, we also are passing in an anonymous function that will handle the results. It is actually within that function that we do the work of formatting the output.
The output comes back as an object, which is an array of objects. Each row returned is an object, and since those are all collected into a result set, an array is used to hold the objects. You can see the returned JSON by uncommenting the line that contains this:

JSON.stringify renders the JSON object back into a string. I recommend that you also copy the output of that string, paste it into the text box found at jsonlint.com, and check it. It will “prettify” the output and validate that it is properly constructed JSON. Since we have an array of objects, our job is to iterate! So we grab each element in the array, using the key values the first time through to build a row “header,” and then we get the properties of each object and concatenate all the values into a comma-separated row. Then we output the whole thing. All of it, except for the database I/O, is pretty standard JavaScript fare.
So, database access looks pretty simple. How about calling a program? Once again, I am thankful that the heavy lifting here was done by folks with spinning propellers on beanie hats that know a lot more about this stuff than I do. Most of that heavy lifting is encapsulated in a module, and it is using the XMLSERVICE library on IBM i to send and return the data needed for each call. Here is what I mean:


What I like about this example, which is found on the IBM developerWorks website, is that the output is displayed in XML as well as JSON format. But, look how little it took to get the command run and returned! Four lines of code, not including comments and formatting. Not much effort. The JSON magic is provided, right now, by the xmlToJson method in the iToolkit. That little ditty is needed because XMLSERVICE uses—well, XML!—to communicate. There is a “pure” JSON version of XMLSERVICE, which I hope goes through a name change before delivery (an XMLSERVICE library that used JSON would be... weird). But perhaps, someday soon, you’ll just be able to specify the language in your call, and it will “speak” whatever you tell it to, XML or JSON. The command call is very similar to other XMLSERVICE examples we have seen in Ruby, Python, and PHP. The RPG program calls should be just as familiar:
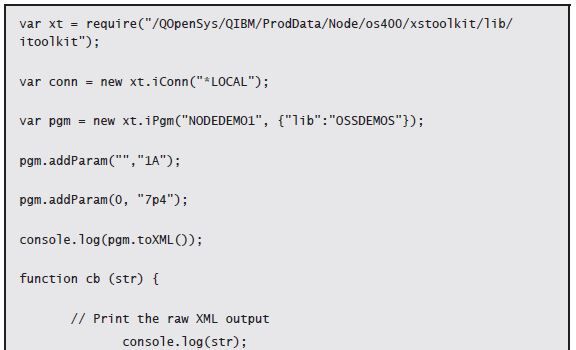

I am going to post the output as well because it will help you to understand the structure of the objects above. Remember, we are “bound” by the way the XMLSERVICE creates the XML output, and all we do is convert the XML to JSON to make for a happy transition to the JavaScript world where objects are king! Here is the output:
<pgm name='NODEDEMO1' lib='OSSDEMOS' error='fast'><parm><data type='1A'></data></parm><parm><data type='7p4'>0</data></parm></pgm>
<?xml version='1.0'?><myscript><pgm name='NODEDEMO1' lib='OSSDEMOS' error='fast'>
<parm>
<data type='1A'>C</data>
</parm>
<parm>
<data type='7p4'>321.1234</data>
</parm>
<success><![CDATA[+++ success OSSDEMOS NODEDEMO1 ]]></success>
</pgm>
</myscript>
JSON: [{"type":"pgm","success":true,"pgm":"NODEDEMO1","lib":
"OSSDEMOS","data":[{"type":"1A","value":"C"},{"type":"7p4", "value":"321.1234"}]}]
Object type:1A value:C
Object type:7p4 value:321.1234
The call to the RPG program using XMLSERVICE is pretty standard. The first three lines load the module, connect to IBM i, and then create a reference to the program to be run on IBM i. The next two lines seem kind of weird because you’d think the program would know what the variables are. But, if you have grappled with the XMLSERVICE library and constructs, you know that it is pretty opinionated. In fact, it has to be opinionated to transition between the unstructured (in some cases) world of open source languages and highly structured world of RPG.
So we have to define the type of parameters passed as well as the values. In Java we would probably use Reflection to find out what the program object needed, but this is RPG, not Java, so we don’t have an RPG program object that can tell us about itself. We define it. And, this is probably the most tedious and error-prone part of using XMLSERVICE. Fortunately, in this example we don’t have many complexities, but some program or API calls can get pretty intense.
I created a callback function to be run when the data returns from the IBM i. This function handles the data coming back, the conversion of that XML into JSON, and then iterating through the objects created except for the conversion to JSON. But, the mystery may be in the code that iterates through the objects. Here is what the JSON looks like:


We have an object {} that has five properties: type, success, pgm, lib, and data. The data property is an array [], and that array has two objects. Those two objects have two properties: a type and a value. So if you were going to “draw” the structure of the object, it would look something like this:
returnedObj
==> data
==>object
==> type
==> value
or in “dotted” notation: retObj.data.object.type.
The kicker here is the data property. Remember that it is property of the object and an object itself. That is why when we iterate through the object array, the array is named data, and we have to use that name to get to the array. Hence the line that says: results.data.forEach(function(data,idx){.... The reference to data seems to appear out of nowhere. In fact, results, which we named, has a property called data that we cannot change because it is a property of the object. data.type is the same way because both type and value are properties of the data object. Yeah, it can get a little hard to unpack sometimes, but jsonlint.com is your friend. When you paste your JSON into that validation window and hit validate, it will check your data and format it nicely. My original output becomes very readable after jsonlint.com gets through with it.
So, that should get you started in Node.js. We saw “bare bones” Node and a Node app that leveraged socket.io and express.js. We looked at calling PASE commands. We looked at database I/O, running IBM i commands, and calling IBM i programs. There is so much more I could walk through with you, but it’s time for you to use your skills and imagination. There are tons of examples out there. Go explore and make them yours!
Check back for more about Open Source for IBM i. Can't wait? You can pick up Peter Helgren's book, Open Source Starter Guide for IBM i Developers at the MC Press Bookstore Today!

Peter Helgren is programmer/team lead at Bible Study Fellowship International. Pete is an experienced programmer in the ILE RPG, PHP, Java, Ruby/Rails, C++, and C# languages with more than 25 years of system 3X/AS400/iSeries/IBM i experience. He holds certifications as a GIAC certified Secure Software Programmer-Java and as an MCSE. He is currently executive vice president on the COMMON Board of Directors and is active on several COMMON committees. His passion has always been in system integration, and he focuses on open-source applications and integration activities on IBM i. Pete is a speaker/trainer in RPG modernization, open-source integration, mobile application development, Java programming, and PHP and actively blogs at petesworkshop.com.
MC Press books written by Peter Helgren available now on the MC Press Bookstore.
 |
Open Source Starter Guide for IBM i Developers Check out this practical introduction to open-source development options, including XMLSERVICE, Ruby/Rails, PHP, Python, Node.js, and Apache Tomcat. List Price $59.95 Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online