








The choice was simple. The license for the data file product we were all using was about to expire, and no one even considered renewing it. For all sorts of reasons, DFU simply didn’t give us what we wanted. As programmers, we were used to getting into databases and fixing data. I knew I could create a utility that did just what I wanted so long as I put the hours in on my own. All that the project required of me was insatiable curiosity, patience, and no one to go home to. That’s how Work with Database File (WRKDBF) was born.
The Systems Programmer’s Reference offered a treasure trove of useful IBM APIs that would help me along the way. That’s the bedrock on which I started—let’s just say I got carried away.
WRKDBF goes back a few years here. I first wrote the program in 1995, before I got my hands dirty with ILE. Yet, even though the AS/400 has moved on, DB2/400 still looks and feels much the same as it did then. This utility copes with most of the day-to-day requirements you can throw at it. Let me share this program with you, but you should not give it to any inexperienced user who could damage sensitive data. Be warned!
I’ll tell you what I planned to achieve, and then, I’ll explain how I set about building it. Everyone has a list of wants and nice-to-haves, and this is mine!
Look Before You Leap: Browsing and Navigation
First of all, I wanted a function that would do the following:
• Show me my data in rows
• Allow me to browse the file vertically through the rows and horizontally across the columns, with screen data fully edited according to the internal database definition
• Navigate to the right record and update it on a detail screen DFU wouldn’t let me do any of that. I had to know the exact key or the record number I was dealing with. Some other utilities work in a browse or detail mode but don’t seem to connect the two. Is that too much to ask?
I wanted the option to browse my keyed file in arrival or in key sequence, to position by key or record number, or to jump to a column (field name). I wanted the capability to call up a list of members so that I could select the right one.
Why clutter the screen with unnecessary data? Surely, I could find a way to filter out all the fields I didn’t want to see so that I could browse and edit only a subset of columns. I also wanted to filter out the rows that didn’t interest me.
Next, I thought it would be good to enter multiple search and replace criteria for mass processing based on simple operators. (Some installations didn’t have SQL, which is better suited to that kind of thing.) I also wanted to be able to scan for more generic values.
I needed to be able to go straight to the bottom of the file (useful in arrival sequence, when you want to check out the latest records) or, of course, to the top. And I didn’t want it to build a huge display subfile just because I went to the end of the file.
The program had to warn me when it suspected invalid data but not refuse point blank to show the data to me. It had to allow me to view, fix, and even set packed data in alphanumeric fields and invalid digits and signs in numerics of all types. And if I wanted to, I should be able to update a record in hexadecimal notation, either field by field or as a single string, like a single-record display of Display Physical File Member (DSPPFM).
The utility had to understand binary and date data types and variable-length fields. It needed to support 10-character field names. I had considered only files created using DDS (as opposed to SQL) at this time.
I wanted the user interface to be simple, with function keys borrowed from common AS/400 programs and subfile options borrowed from SEU and other standard AS/400 panels (2 = Change, 4 = Delete, etc.). I expected users to be able to pick up on the familiar function keys and subfile options easily. In fact, you’ll probably recognize most of them.
For reasons that have more to do with fastidiousness than anything else, I wanted full, context-sensitive help, so I decided to put all my language constants (barring help) in the same message file as the error messages so they could be easily customized or translated.
As you can see, my planning generated a long list of requirements, but the truth is that I built them in gradually!
Putting It All Together
If you download the code for this utility, which is available at www.midrangecomputing.com/mc/99/08, you immediately notice that it’s not ILE. I make no apology for that. Although the design might show the age of the utility’s inception, the program does include all the latest features IBM’s developers built into RPG III (up to OS/400 V3R2) before turning their attention fully to RPG IV. I could have converted it, but there didn’t seem any point, since it would take some reengineering to make it worth the while.
RPG III, designed to reserve fixed amounts of memory, might not be the best language for this sort of utility. To make this utility work with large files holding many fields, I had to create large work fields: large arrays, large multiple-occurrence data structures. Nevertheless, on any modern enterprise machine—even a development one—the resource overhead has become insignificant, and it usually outperforms Update Data (UPDDTA). Just be careful if you have a truly monstrous record length; the utility has its limits.
In addition to RPG III, I used standard CL, commands, display and printer files, a panel group, and a message file.
How to Access Your Files
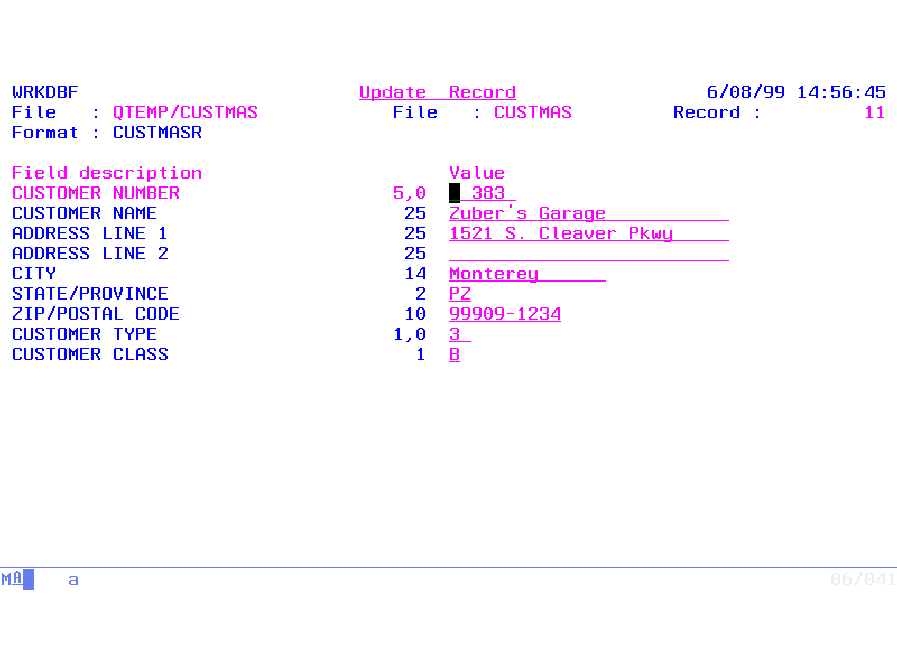
If you look at the command prompt for WRKDBF (see Figure 1), you see only a few parameters. You tell the command what file you want, where it is, what member you wish to view (you can use *SELECT to choose from a list), and whether you want to access it in Update or Display (read-only) mode. You also tell it whether you want to access the database by key (default) or arrival sequence.
In the accompanying command, Display Database File (DSPDBF), which uses all the same programs, the display/update option is a constant, D. You can deploy this command as a general file viewer with different access authority.
The command-processing program, WRKDBFC, does preliminary checks. It makes sure the file exists and the member exists (unless it’s a DDM file), and it invokes the necessary overrides.
The main RPG program, WRKDBFR, handles the access by declaring four program-described files. Two are update, and two are read-only. Within each of these two groups, one file is keyed, and the other is not. These files have the maximum record length that’s usable in RPG III program-described files, 9,999 bytes, and the key can be only 99 bytes long. (This doesn’t prevent you from using files with longer keys; it just stops you from positioning to a specific record.)
Each file has its own information data structure (INFDS). Also, these files are opened with SHARE(*YES), as is the display file. This is because the updates don’t actually occur in WRKDBFR. They’re in WRKDBFR2 (detail display and update) and WRKDBFR3 (mass processing), and I keep the files open for a smaller open data path overhead.
WRKDBFR is smart enough to open the read-only files if it is dealing with a logical file that cannot be updated or if you don’t have update authority. And remember that it will always open the arrival sequence file that will be needed by the detail display and update, which works by relative record number. (The file’s key might not be unique!)
Analyze This
How do you convert raw data into a database display? Wherever possible, I’ve used APIs. However, I did make use of one standard non-API technique. To analyze the keyed access path, I used the output file created by the DSPFD command, TYPE(*ACCPTH). The file used is also declared in WRKDBFR and read into storage for key positioning where required.
The program uses the QUSLRCD (List Record Formats) API to build a record format list into a user space. More than one format will trigger an error message; I never got around to supporting multiple-format logicals.
Then, the program builds a list of fields in a user space using the API QUSLFLD (List Fields). It also has to build the user space objects it needs (in QTEMP) on its first run, so it takes a little longer the first time you use it. If you repeatedly access the same file, though, you’ll notice that it won’t refresh the field list in the user space as long as the format identifier is the same.
The fields are loaded into a multiple-occurrence data structure, which is also passed to the subprograms. This tells the program the buffer position, type, and length of the fields in the database file. After that’s done, you have all you need to know to work with the data!
Playing the Numbers Game
One of the trickiest things that the program had to handle was numbers. The conversion of packed or even binary data to an edited, displayable format required some thinking.
In the end, the approach I adopted was to have a common routine for preparing and editing zoned numerics (database data type S) and to convert packed and binary data to zoned internally before performing the common routines. Subroutine MOVPCK will show you how the packed field is converted to an editable number.
With packed and zoned numbers, you need to know what the machine accepts as valid signs. In my case, I’ve allowed F and C as valid positives and D as negative. Valid- signed bytes are defined as comparison strings, with the sign placed in the high-order or low-order byte as appropriate.
To edit the prepared zoned numbers, I used (you guessed it) more APIs—in this case, three separate ones (see subroutine EDIT):
• QECCVTEC to obtain an internal edit mask based on edit codes
• QECCVTEW to obtain an edit mask based on an edit word
• QECEDT to apply the edit mask to the number itself The default edit code when no editing is given is J, and edit codes defined in the database that do not have signs (1, 2, 3, and 4) are replaced with those that do. (If there’s a negative value, you’ll want to know!)
You will find this technique in the detail program WRKDBFR2 also.
The Devil’s in the Detail
The browse screen (Figure 2) is built by reserving a column width for each field, allowing enough space for the edited field value or the column headings, whichever is the greater.
Clearly, however, the business end of a file utility lies not really in the browsing. That’s just the way of getting to what you really want to do: updating the data. For that, you need the detail display.
To create, update, copy, display, print, or delete an individual record, the responsibility is passed to subprogram WRKDBFR2, which builds a display subfile of the fields. In all but one instance (printing), the subfile appears. The program also receives a list of selected fields in case you filtered out most of them in the browse. Then, it displays (and allows update to) only that list.
To handle updates, WRKDBFR2 defines an array called DATA that is distinct from the file input buffer. Data passes back and forth between the screen and this array with each subfile change. Remember, WRKDBFR2 always retrieves and updates the arrival sequence file.
As with the browse function, a function key (F2) toggles between showing the field names and their descriptions. Figure 3 shows a detailed record display in normal mode.
If the fields are open (on create, update, or copy), the numeric fields appear without thousand separators but with signs, as in edit code L; otherwise, they are fully edited. Also in open mode, a nondisplay attribute byte is placed at the end of the field to act as a guide. You can type over it, but the program knows how long each field should be, including signs and decimal points, and will validate the input. With variable-length fields, it removes the leading two bytes and builds the length based on their binary value. (Edit past this length, and the program updates the leading bytes accordingly.)
Function key F10 creates a parallel subfile with hexadecimal display values, which you can then edit (see Figure 4). Variable-length fields show their leading binary bytes. Hexadecimal values were easy to build in. I just had to use data structures with carefully initialized hexadecimals values linked directly to array names so I could use the LOKUP op code. There is a cross-reference between true values and display hexadecimal values.
If you want to look at the record as a single hexadecimal string, press F11 from normal mode. Here, you can overtype either character or hexadecimal (use F10 as a toggle) and locate a field within the string using the right function keys. You can even inquire as to what field your cursor is currently positioned over. This is all possible because of the multiple-occurrence data structure built into the browse program. Figure 5 shows how this screen looks.
Serious Updates: Mass Processing
Back in that browse program, function key F15 takes you to a mass-process feature that allows you to find or update records. With the Find option, you can enter up to 20 field specifications, including AND and OR specs, with operators such as EQ, GE, ST (starts with), and SC (scan for in). All these operators have symbolic equivalents (=, <>, >=, and so on).
With the Update option, before you set the search criteria, you must specify which fields you want to update and what their values should be. You can also set your search criteria to *ALL (in the first field) so that the update applies to all records up to a given limit count.
The search is not fast, as the program has to convert the data in each record’s compare fields. If you have access to SQL, use it instead of WRKDBF for large file updates.
Grow Your Own
If you want to try WRKDBF for yourself, download the code. The utility comes with a lot of source code, so make sure you read the READ.ME file first. It has specific instructions so you don’t experience too many problems. Although there are a lot of steps to follow, I’ve tried to make it as painless as possible.
The trickiest thing you’ll deal with is the message file. If you download the code, you must also download a text data file and a CL program (CRTMSGF) to create a message file from the text. Customize the constants and error messages in the message file if you want a translation. You’ll have to edit and compile the panel group separately to translate the Help.
For those who can’t be bothered, I have a zipped save file that you can FTP and restore as an easy option. Contact me if you have any problems.
And Finally...
I’ve not had time to describe all the functions available in this tool, so use the online help. Function keys are accessible by pressing F1 or the Help key and then F2 for Extended Help.
If you get tempted to edit the source or change the message file, exercise caution. Make a backup of all the originals. Don’t be fooled by the existence of language program constants; most of them have been externalized to the message file.
Please remember that you use this utility at your own risk and that I can’t be held responsible for data corruption resulting from its use. It does have some limitations (seriously big record lengths, for example). If you’re worried, use it initially on test data only.
 |
 |
 |
 |
 |
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online