









Avoid common SQL programming mistakes that can drag application performance.
In this final installment of this DB2 for i coding series, I’ll discuss two items. First, I’ll examine a reason why a query that once performed well when it was first written might become lethargic as time passes. Second, I’ll discuss a way to potentially improve the performance of multi-row update statements. In the end, the lessons are how to avoid some common coding flaws that can take the wind out of your database sails.
(Editor’s note: Links to parts 1–5 of this series are at the end of this TechTip.)
Be Wary of Queries Using Complex Views
Programmers don’t like programming the same thing over and over, so naturally they reuse code when possible. In DB2 for i, one popular mechanism for code reuse is a view. Often, the views start out simple but become complicated over time as an increasing number of useful expressions and tables are innocently added to the view.
Take, for instance, a simple view to get an individual customer’s information from the AdventureWorks sample database:
CREATE OR REPLACE VIEW vIndividualCustomer
AS
SELECT
p.BusinessEntityID
,p.Title
,p.FirstName
,p.MiddleName
,p.LastName
,p.Suffix
,pp.PhoneNumber
,pnt.Name AS PhoneNumberType
FROM Person p
INNER JOIN Customer c
ON c.PersonID = p.BusinessEntityID
LEFT OUTER JOIN PersonPhone pp
ON pp.BusinessEntityID = p.BusinessEntityID
LEFT OUTER JOIN PhoneNumberType pnt
ON pnt.PhoneNumberTypeID = pp.PhoneNumberTypeID
WHERE c.StoreID IS NULL
Because it’s a tad difficult to remember how to differentiate customers who are individuals from customers that are organizations, developers come to rely heavily on this view within their individual sales-related queries. As you might imagine, over time, all kinds of useful info is added to the view, and after a year or two, the view grows to this monstrosity:
CREATE OR REPLACE VIEW vIndividualCustomer
AS
SELECT
p.BusinessEntityID
,p.Title
,p.FirstName
,p.MiddleName
,p.LastName
,p.Suffix
,pp.PhoneNumber
,pnt.Name AS PhoneNumberType
,ea.EmailAddress
,p.EmailPromotion
,"at".Name AS AddressType
,a.AddressLine1
,a.AddressLine2
,a.City
,sp.Name AS StateProvinceName
,a.PostalCode
,cr.Name AS CountryRegionName
,p.Demographics
FROM Person p
INNER JOIN BusinessEntityAddress bea
ON bea.BusinessEntityID = p.BusinessEntityID
INNER JOIN Address a
ON a.AddressID = bea.AddressID
INNER JOIN StateProvince sp
ON sp.StateProvinceID = a.StateProvinceID
INNER JOIN CountryRegion cr
ON cr.CountryRegionCode = sp.CountryRegionCode
INNER JOIN AddressType "at"
ON "at".AddressTypeID = bea.AddressTypeID
INNER JOIN Customer c
ON c.PersonID = p.BusinessEntityID
LEFT OUTER JOIN EmailAddress ea
ON ea.BusinessEntityID = p.BusinessEntityID
LEFT OUTER JOIN PersonPhone pp
ON pp.BusinessEntityID = p.BusinessEntityID
LEFT OUTER JOIN PhoneNumberType pnt
ON pnt.PhoneNumberTypeID = pp.PhoneNumberTypeID
WHERE c.StoreID IS NULL
This hypothetical view grew from four joins to ten joins. Now let’s turn our attention to a sales query written long ago that hosts this view:
SELECT soh.SalesOrderId,soh.OrderDate,soh.DueDate,soh.ShipDate,
soh.PurchaseOrderNumber,soh.AccountNumber,
soh.CustomerId,
sod.OrderQty,sod.ProductId,sod.UnitPrice,
indiv.FirstName,indiv.LastName,
indiv.EMailAddress
FROM SalesOrderHeader soh
JOIN SalesOrderDetail sod ON sod.SalesOrderId=soh.SalesOrderId
JOIN vIndividualCustomer indiv ON indiv.BusinessEntityId=soh.CustomerId
ORDER BY soh.SalesOrderId,indiv.EMailAddress
The good news is, as the view changed over time, this query didn’t need to be refactored. The bad news is, the increasing complexity of the view slows down the query. This query only needs three columns from the view and certainly doesn’t require information from all ten underlying tables. So, what is the cost to the query for utilizing an over complicated view?
Figure 1 below shows the Visual Explain graph for the query plan, and it’s easy to see the plan has a large number of steps to process:
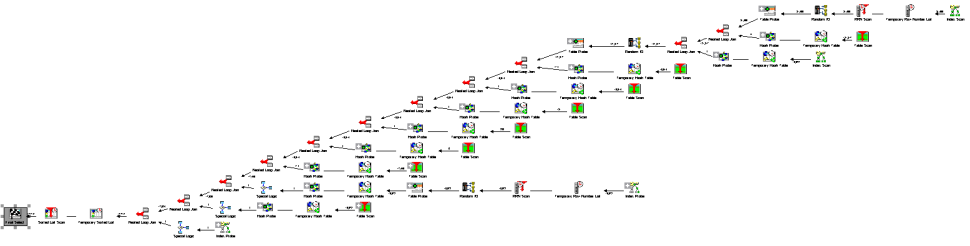
Figure 1: When utilizing the complex view, the parent query boasts a large number of steps to process, including accessing tables that aren’t required for the query.
Now, let’s consider refactoring the query so that it uses only the tables that are needed:
SELECT soh.SalesOrderId,soh.OrderDate,soh.DueDate,soh.ShipDate,
soh.PurchaseOrderNumber,soh.AccountNumber,
soh.CustomerId,
sod.OrderQty,sod.ProductId,sod.UnitPrice,
p.FirstName,p.LastName,
ea.EMailAddress
FROM SalesOrderHeader soh
JOIN SalesOrderDetail sod ON sod.SalesOrderId=soh.SalesOrderId
JOIN Person p ON p.BusinessEntityID=soh.CustomerId
LEFT OUTER JOIN EmailAddress ea
ON ea.BusinessEntityID = p.BusinessEntityID
ORDER BY soh.SalesOrderId,ea.EMailAddress
It turns out that there are only two tables needed from the view vIndividualCustomer to support the existing three columns from the view. Further, the JOIN to the Customer table and the filter “StoreId IS NULL” aren’t even required for the refactor.
After the refactoring, Visual Explain shows a much easier to digest query plan (see Figure 2 below):

Figure 2: The query plan is much simpler for DB2 to process than the original when only the four necessary tables are being accessed.
If your organization is looking for ways to get performance gains, consider refactoring queries that use views that have “grown” over the years. It may be worth refactoring a query by updating the complex view reference with a simpler view or with the base tables. This is one of those areas where a query may perform well early on when the developer finished writing the code and the data set was small, but it slows over time as the data grows.
Beware: Refactoring queries that use complex views to use base tables can be tricky. A subtle accidental change such as an INNER JOIN for a LEFT JOIN or placing a WHERE predicate on a LEFT JOIN can change the behavior and results of a query. Always test to make sure your refactor produces the same result as the original (or be able to justify any changes in behavior after the refactor is done.)
As an aside, I typically use the EXCEPT set operator to verify that everything is the same between two queries. Here is how I tested the refactoring of the above query:
SELECT soh.SalesOrderId,soh.OrderDate,soh.DueDate,soh.ShipDate,
soh.PurchaseOrderNumber,soh.AccountNumber,
soh.CustomerId,
sod.OrderQty,sod.ProductId,sod.UnitPrice,
p.FirstName,p.LastName,
ea.EMailAddress
FROM SalesOrderHeader soh
JOIN SalesOrderDetail sod ON sod.SalesOrderId=soh.SalesOrderId
JOIN Person p ON p.BusinessEntityID=soh.CustomerId
LEFT OUTER JOIN EmailAddress ea ON ea.BusinessEntityID = p.BusinessEntityID
EXCEPT
SELECT soh.SalesOrderId,soh.OrderDate,soh.DueDate,soh.ShipDate,
soh.PurchaseOrderNumber,soh.AccountNumber,
soh.CustomerId,
sod.OrderQty,sod.ProductId,sod.UnitPrice,
indiv.FirstName,indiv.LastName,
indiv.EMailAddress
FROM SalesOrderHeader soh
JOIN SalesOrderDetail sod ON sod.SalesOrderId=soh.SalesOrderId
JOIN vIndividualCustomer indiv ON indiv.BusinessEntityId=soh.CustomerId
EXCEPT will only show rows from the upper query that aren’t present in the lower query. Since the query results should be identical, this query should return zero rows. Thereafter, I reverse the order of the queries (using EXCEPT again) and verify that the result is zero rows.
Another downside of refactoring views is you lose code reusability. It’s just one of those tradeoffs software engineers may have to make when squeezing out optimal performance is the primary objective.
Don’t Perform Unnecessary Updates
This one is an often overlooked “no brainer.” Many times an UPDATE statement is invoked to ensure that rows among correlated tables are synchronized, as shown in this example:
-- Update Product List Price
UPDATE Product p
SET ListPrice=(
SELECT ListPrice
FROM ProductListPriceHistory plph
WHERE p.ProductId=plph.ProductId
AND CURRENT_DATE BETWEEN plph.StartDate
AND COALESCE(plph.EndDate,'2099-12-31'))
WHERE EXISTS (
SELECT *
FROM ProductListPriceHistory plph
WHERE p.ProductId=plph.ProductId
AND CURRENT_DATE BETWEEN plph.StartDate
AND COALESCE(plph.EndDate,'2099-12-31'))
But what if the majority of the rows are already in sync and no updates need to be done? Wouldn’t it be a waste of resources to have DB2 perform a meaningless change the values in various columns? The answer is yes, and an easy workaround is to add predicates to prevent an UPDATE when the values already match. An example of this is shown here:
-- Update Product List Price
UPDATE Product p
SET ListPrice=(
SELECT ListPrice
FROM ProductListPriceHistory plph
WHERE p.ProductId=plph.ProductId
AND CURRENT_DATE BETWEEN plph.StartDate
AND COALESCE(plph.EndDate,'2099-12-31'))
WHERE EXISTS (
SELECT *
FROM ProductListPriceHistory plph
WHERE p.ProductId=plph.ProductId
AND CURRENT_DATE BETWEEN plph.StartDate
AND COALESCE(plph.EndDate,'2099-12-31')
AND p.ListPrice<>plph.ListPrice)
The bolded line predicate at the bottom of the WHERE EXISTS clause simply adds the condition that the ListPrice needs to be different between the tables in order for an UPDATE to occur.
As mentioned earlier in this series, reducing the amount of rows changed by DB2 will potentially save time elsewhere, such as trigger executions, placing locks on rows, writing journal entries, checking constraints, and the like.
Become Better Acquainted with DB2
An old proverb says “A righteous man regardeth the life of his beast.” In other words, a good farmer is wise to care for his animals and understands their value. I’ll modernize the proverb to “A wise developer regardeth the load of his database server.” The lesson throughout the series? Don’t load down your database server with unnecessary work.
When programming DB2 for i, it’s important to be aware of how DB2 processes things. I will give kudos to IBM as they have done a great job of making this database engine great. In fact, I found that many of the problems I was familiar with (as of V5R2 - V5R4 era) and set out to write about in this series are no longer problems.
This series was intended to convey using simple examples of how to code. A quick review of the other lessons are:
- Use UNION ALL instead of UNION when combining result sets where there will never be a duplicate among the rows in both sets. This will save DB2 from doing unnecessary sorting and filtering.
- Sometimes it’s beneficial to combine small successive DML statements into a single statement in order to prevent unnecessary trigger, constraint, and journal processing.
- Be sure to CAST data types appropriately when joining tables with different (potentially incompatible) data types.
- Remember not to mask predicates with unnecessary functions or expressions that may prevent DB2 from using an index or column statistics.
- Be careful when using ORs for a query’s primary selective criteria as it may prevent DB2 from using an index, resulting in an expensive table scan.
- When testing for the presence of a row, using an EXISTS predicate is more efficient than using a COUNT aggregate expression and can also be used in place of a JOIN/DISTINCT combination.
- Be careful about using expensive scalar user-defined functions (UDFs). Where possible, make sure your functions are deterministic, which may allow DB2 to cache the UDF’s values.
- Do not use cursor (aka row by row) processing unless it’s absolutely necessary. DB2 is optimized for set-based processing. Be sure to review the newer features in DB2 for ideas on how to rid your code of unnecessary cursor processing.
- Keep your temporary tables as small as possible!
References
DB2 for i Optimization Strategies, Part 1
DB2 for i Optimization Strategies, Part 2
DB2 for i Optimization Strategies, Part 3
DB2 for i Optimization Strategies, Part 4
DB2 for i Optimization Strategies, Part 5
 IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
LATEST COMMENTS
MC Press Online