















Driven by regulatory compliance issues and the ever-growing threat of compromised private data, more and more organizations are starting encryption projects. When done right, encryption can add a layer of defense on top of the good access controls already protecting your data.
However, careful planning and architecture is required before leaping into the implementation phase of your encryption project. Without proper planning, you could find that private data remains unencrypted, encrypted data is no more secure than unencrypted data, or the encrypted data is unrecoverable. Therefore, it's critical to plan and carefully architect your encryption implementation.
Understand the Purpose of Your Project
To avoid an improper implementation, you need to need to understand why the data is being encrypted. For example, if complying with a standard such as the Payment Card Industry's (PCI) Data Security Standard, you must carefully read and understand its requirements. The PCI Data Security Standard has detailed encryption requirements as well as requirements for managing the encryption key. If your implementation does not follow these requirements, it will be out of compliance and you may fail your PCI audit.
Many of you are considering encryption—especially of backup tapes—to avoid the state notification law requirement of notifying individuals when their personal data is lost or stolen. Even if the law or regulation doesn't specify detailed encryption requirements (such as which encryption algorithm must be used to avoid notification requirements), I encourage you to architect your implementation as though you were meeting a standard such as the PCI's. You might as well implement a strong encryption scheme with strong key management processes in case the laws change and start specifying strict requirements (or your business changes and you suddenly find yourself having to comply with a strict law or regulation). In other words, if you're going to the trouble of implementing encryption, you might as well do it right.
Identify the Scope of Your Project
The first step in identifying the scope of your encryption project is determining what data is going to be encrypted. This decision should not be made solely by either a system administrator or a programmer; it should be decided with the help of the data owners and the person(s) playing the roles of chief information officer, chief compliance officer, and chief security officer. You may even choose to include your organization's legal counsel. Why? Because no single person is aware of all the regulations that determine what constitutes private data, all the laws and regulations that govern protection of private data, all the legal ramifications of not protecting the data or having the data compromised, all the places where the data is stored and how it is used, and last, but certainly not least, the effect on the organization should the data be compromised. To do this project properly, you need input from numerous individuals in your organization. Only after you gather this input can you know the true scope of your project and decide how to proceed.
Let's look at the steps you need to take to determine the scope of your project.
Step 1: Determine What Data Needs to Be Encrypted and When
The laws and regulations with which your organization must comply typically dictate what data needs to be encrypted and when. For example, if your organization stores credit card numbers, the PCI Data Security Standard dictates that the transmission of credit card information must be encrypted as well as any credit card information that is "at rest" (stored.) If you're storing protected electronic healthcare information, HIPAA dictates what needs to be encrypted. It recommends that data at rest be encrypted but doesn't require it. It does, however, require that data transmitted outside of the organization's network be encrypted. Your organization might have a trading partner with encryption standards required to fulfill its service agreement. Finally, the data owners may specify that all backups of their data need to be encrypted because of the privacy of the data (for example, social security numbers or bank account numbers) or its importance to the company (intellectual property, specialty vendors, etc.).
Step 2: Determine Where the Data Is Stored
Determining what data to encrypt is the easy step. When specific data residing in a database is to be encrypted, the more difficult task is determining all—and I do mean all—of the places the data resides. Without fail, private or confidential data resides in more places than first come to mind. To ensure the location list is complete, you need to assemble selected programmers, system administrators, data owners (such as the lead HR administrator), database administrators, system analysts, and perhaps representatives from your third-party software vendors. Beyond finding all of the physical files in which the data resides, you can't forget the private information residing in spooled files, outfiles, query files, text files, stream files, and printed reports. Also make note of databases replicated to high availability (HA) machines, databases residing on development machines (including copies of the production database made into developers' libraries), logical files that include the fields needing to be encrypted, and data propagated to network servers or data warehouses along with desktop applications such as Excel.
After listing all of the places where the private data resides, examine each instance and determine whether the private data is actually required for that specific instance or can be eliminated. In many cases, you can significantly reduce the scope of your project (as well as the exposure to your organization's private data) if you stop storing the private data on servers, stop allowing it to be included in queries, create a logical file that does not include the fields with private data, and eliminate the private data from printed reports and Excel spreadsheets. Often, the data is included in these places simply because it's part of the information in the original file structure, not because it's actually necessary.
Here are a couple of examples to consider. Do credit card numbers really need to be included on a printed report of all returns to a store if the person viewing the report is interested only in what's being returned and the reason for the return? Doubtful. Without question, removing the credit card number from the report is much easier than adding logic to the application to allow this individual to first encrypt this instance of the data and then decrypt it when the report is generated. It also eliminates the problems of putting appropriate access controls on the file, adding routines to encrypt the credit card number, and dealing with the proper disposal (shredding) of the printed reports.
Should the entire employee master file be available to all employees? No, but it often is because the employee extensions are in the file and the online phone directory needs access to this information. To solve this issue, the solution is to either move the phone extensions to another file or provide a logical file over the employee master that provides only the employee extensions, not all fields in the file.
Step 3: Determine How the Information Is Being Used
This step, while easier than step 2, still usually requires an assembly of individuals. You need to understand how the data is being used so you can determine what type of encryption is required. For example, if the data is a social insurance number (in Canada) or a driver's license number used only for verification purposes, you can likely store it in a one-way hash. A hash cannot return the original data; it's one-way only. Using a hash algorithm is more simple and more secure than implementing more-complex encryption algorithms that allow decryption of data.
To ensure encryption provides an additional layer of protection on top of the access controls you have on database files, you must limit the scenarios where the data is decrypted. For example, if the data is being sent to a bank for transaction processing or to a clearinghouse for verification, cleartext data is required. For this scenario, determine how and when to decrypt the data so that the time the data is in cleartext is as short as possible. Also, once the cleartext data has been transmitted over an encrypted session, the cleartext data needs to be removed or cleared as soon as possible.
Types of Encryption
As you research your encryption project, you'll read about three types of encryption algorithms (Figure 1):
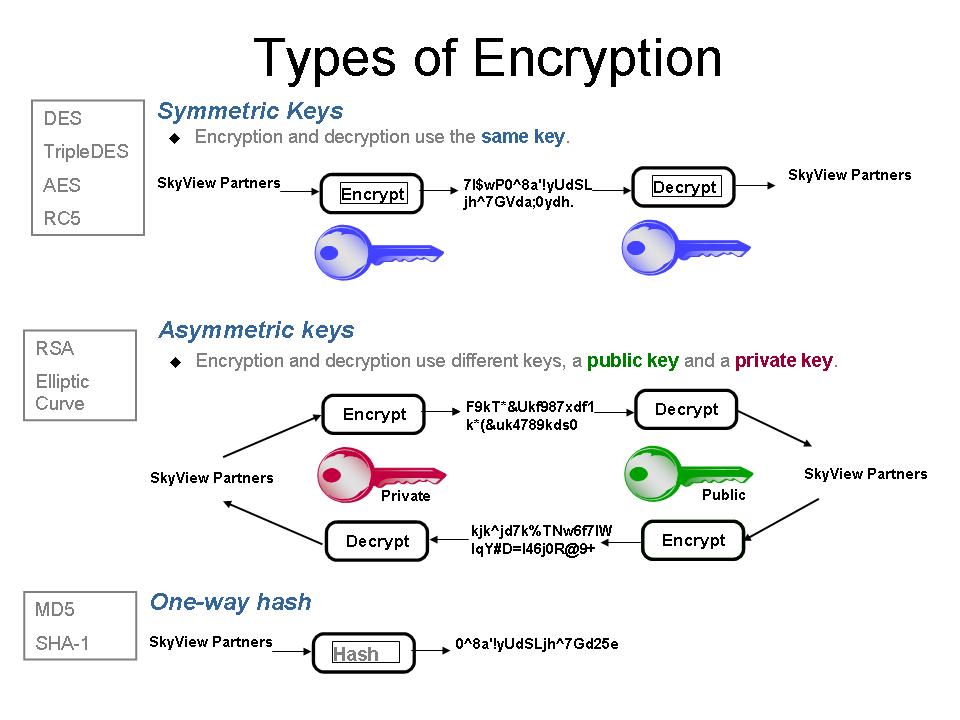
Figure 1: You'll need to consider these three types of encryption algorithms for your encryption project. (Click image to enlarge.)
- Symmetric key algorithms use the same key to both encrypt and decrypt data. They are generally faster than asymmetric key algorithms and are often used to encrypt large blocks of data. Algorithms you'll hear mentioned include DES, TripleDES, RC5, and AES (the standard for the U.S. government). Either TripleDES or AES is required when encrypting stored credit card numbers.
- Asymmetric key algorithms require two encryption keys: one to encrypt the data and the other to decrypt the data. It doesn't matter which one does which function; it's just that you can't use only one key to both encrypt and decrypt data. These algorithms are typically used for authentication; for example, they're used during an SSL or VPN "handshake" to verify that the client knows the server to which it's trying to connect. Once the verification is complete, a "session key" is exchanged by the client and server, and symmetric key encryption is used for the actual data transmission. Asymmetric key algorithm types include RSA and Elliptic Curve.
- Hash algorithms produce a result that is not decryptable. They are typically used for comparing two values to ensure they're the same. For example, digital signature verification uses a hash function to ensure that the signed document has not been altered. Because a hashed value cannot return the original value, this method provides the most secure form of storing data and is the most appropriate method when the original (cleartext) form is not required. MD5 and SHA-1 are two examples of hash algorithms.
What Are the Challenges?
The challenge of transmitting data encrypted has been solved by most organizations. They typically use either the integrated i5/OS functions (e.g., HTTPS, secure FTP) or a vendor solution. Today's challenges lie in determining whether and how to encrypt backups and how to encrypt data in database files.
Before we discuss the details of these challenges, I'd like to discuss an even larger challenge: encryption key management.
The Key Is Key Management
Without good key management, your encryption project will likely be a disaster and provide absolutely no additional layer of security for your data. I cannot emphasize this point enough. The encryption key is the most vital part of your encryption algorithm. Possessing the encryption key when data has been encrypted using a symmetric key algorithm means that the data can be decrypted. It is critical that this key be managed properly. Here are best practices for key management.
Separation of Duties
The person who creates the keys should not be the same person using the keys (writing programs to use the keys for encryption or decryption) or the custodian of the keys. For large organizations, this shouldn't be an issue. For small System i shops, this may present a challenge. Either way, you must be prepared to explain your separation of key management duties to any auditor who asks.
Creating the Keys
Creating strong encryption keys requires seeding the key-generation algorithm with a random number. You might think it sufficient to simply type in a set of numbers for the algorithm seed number; after all, it looks random to you, right? However, studies show that people type in a certain pattern; therefore, the key is not actually random but a manifestation of the person's typing pattern. A weak seed means that your encrypted data is more weakly encrypted and more easily decrypted. You need to use a formal random number generator, such as the one provided by the i5/OS CIPHER MI instruction, to obtain the seed for your key-generation system.
Changing the Keys
You must be prepared to explain to auditors your process for changing encryption keys. If a breach occurs or you become aware that the encryption key has been compromised, you will have to decrypt the data and re-encrypt it using a different key. Best practices require that keys—regardless of whether they have been compromised—should be changed every year or two. The exception to this rule is when you feel that there would be more chance of a compromise to the data by decrypting and re-encrypting it than leaving it encrypted with an old key. Whether or not you plan to change keys on a regular basis, you need to establish and document a policy reflecting your key management change practices. Items to consider are the possibility that you will go back and decrypt and then re-encrypt all data that's been backed up, the safest system for the decryption/re-encryption to occur, and so forth.
Storing the Keys
Appropriate placement and access control of stored keys is vital. Many people think they need to keep their encryption algorithm a secret, but the critical component to keep secret is the encryption key. Therefore, storing keys in cleartext in program source or in a data area is not a good idea. One choice is to use a validation list for secure storage of keys, which is your best integrated i5/OS option if you are running prior to V5R4. (Validation lists provide a method for storing and encrypting small amounts of data such as encryption keys.) Beginning in V5R4, you should use the i5/OS integrated key-management APIs. If you're choosing a vendor encryption product, make sure you understand its key management features to ensure they meet your requirements.
Controlling Access to the Keys and Encryption/Decryption Routines
Without good access controls (that is, object security) on where the encryption keys are stored as well as on the encryption and, especially, the decryption routines, you get virtually no additional security benefit by encrypting data in a database. If everyone has access to the decryption key, what's the point of encrypting the data?
In addition, you must realize that you cannot protect your encrypted data from being decrypted by an *ALLOBJ user. Remember, users with *ALLOBJ special authority can access any object on the system (this is why I prefer to use hashes whenever possible). The best you can do to ward off access by *ALLOBJ users is to throw up some roadblocks to make it more difficult to run the encryption routine and thus discourage them from trying to decrypt the data. One such roadblock is to query the process to see if it's running with *ALLOBJ and, if it is, reject the request. Another is to check the program calling the decryption routine and decrypt only if the calling program is in an approved list. But beware: No software method is a perfect prevention mechanism against abuse by an *ALLOBJ user. If your organization requires protection against an *ALLOBJ user decrypting data, you must use a hardware encryption mechanism that provides separation of roles and duties apart from i5/OS profiles.
Now let's take a look at the issues surrounding the two methods people are currently most interested in: encrypting backups and encrypting a field in a database file.
Encrypting Backup Media
Two popular methods exist for encrypting backup media. One is to save the data to a save file (*SAVF), encrypt the *SAVF, and then save the encrypted *SAVF to the media. This method requires that there be storage available for the *SAVF. Depending on how much data is being saved, the amount of storage used can be significant. Therefore, this method may not be a viable solution for some organizations. The other method is a hardware solution in which the device performs the encryption before the data is written to media or the encryption feature is integrated into the tape drive itself. Using a hardware solution removes the requirement for the intermediate save file.
Rather than encrypt data on the media, some people use compression software, which reduces the space required for the backup data and also produces what I call "mangled" data. While mangled data is not easily read, it is not the same as encrypted data, and it may not meet the requirements of the laws or regulations with which you need to comply. Before implementing this technique, make sure this solution meets your requirements.
Whatever method you choose, there are some key points to consider:
- How are you going to ensure separation of duties?
- Who will maintain the keys, and will they be available when a library needs to be restored?
- How does an encrypted backup affect your organization's disaster recovery planning? For example, does your hot site have the proper equipment to decrypt your encrypted save tapes?
- Do you have the proper configuration to support encrypting your backup? For example, if you are encrypting your entire system's save, you need to ensure your key management system is in a partition whose save is not encrypted; otherwise, you won't be able to recover your system.
- Will the encryption process increase your save times? Software encryption solutions can lengthen the time in which backups complete. (Hardware solutions usually don't, but check with the vendor.) Can your organization absorb this extra time for backups?
Encrypting a Field in a Database File
IBM provides several options for encrypting data in a database field. The most rudimentary one (but the only one provided before V5R2) is coding to the CIPHER machine instruction. If you're running V5R3, APIs are integrated into i5/OS that provide software encryption functionality. A subset of this function is available via PTFs in V5R2. Finally, for the most secure method, as well as the most complex, you can install a FIPS-compliant hardware cryptographic coprocessor card and write to the APIs provided. The crypto card is the only IBM solution that provides encryption key management features prior to V5R4. It also provides separation of roles apart from i5/OS user profiles.
Documentation for all of these encryption methods can be found in IBM's Information Center. However, writing to these interfaces yourself without some knowledge of encryption methodology will typically result in a less-than-optimal implementation. In other words, programmers should become familiar with encryption methodologies before attempting to implement these APIs.
Another IBM solution is to use one of the SQL encryption keywords. Just as with the i5/OS APIs, care must be taken with key management to ensure the key is never stored or transmitted in cleartext.
You may feel that writing to the encryption APIs is more than you want to tackle. If so, several vendors provide solutions for database encryption. When investigating these solutions, make sure you understand their key management capabilities to ensure they meet your project requirements.
If you write to the software APIs yourself, some amount of re-architecting may be required, although the vendor solutions try to minimize that. The ideal solution is to re-architect your application and move the private data into its own database, using a separate database for each type of private data (e.g., one for cardholder data, another for HR data). This method makes it much easier to ensure the encryption/decryption functions are called only when necessary, which helps keep the data secure. It also helps minimize the effect of encryption on system performance because the data is decrypted only when necessary, not on every file open. Additionally, you are in a much better position to respond quickly should the encryption requirements change in the future.
If moving the data to another file is not an option, you will most likely have to declare a new field for the encrypted value because the encrypted value is almost always significantly larger than the original value. Once the encrypted field is populated, you'll have to take steps to neutralize or otherwise "wipe out" the cleartext version of the private data currently residing in the file.
Again, you need to restrict when the data is being decrypted. Using a trigger program that blindly decrypts the data whenever the file is opened defeats most—if not all—benefit gained by encrypting the data. Make sure that when you implement your decryption scheme, it is invoked only when the cleartext data is required.
Disaster Recovery Considerations
When planning your encryption project, don't forget to take into account the impact on your disaster recovery plans. If the media is encrypted, keys will need to be available at your alternate location so that media can be read and data restored. If a hardware encryption method was used (for either encrypted backups or encrypting data in database files), the same hardware must also be available at your recovery site. Finally, when encrypting data while it's being transmitted, you have to make sure that you have the appropriate digital certificates installed in your servers or VPN configurations.
Success Depends on Planning
An encryption project should not be taken lightly. Your organization's data is a vital asset; that's why you're considering an encryption project. Carefully implement the architecture you have chosen. An architecture is only as good as its implementation. Done right, encryption adds another layer of security for protecting data. Done improperly, the data may not be available when you need it.
Carol Woodbury is co-founder of SkyView Partners, a firm specializing in security policy compliance and assessment software as well as security services. Carol is the former chief security architect for AS/400 for IBM in Rochester, Minnesota, and has specialized in security architecture, design, and consulting for more than 16 years. Carol speaks around the world on a variety of security topics and is coauthor of the book Experts' Guide to OS/400 and i5/OS Security.

Carol Woodbury is IBM i Security SME and Senior Advisor to Kisco Systems, a firm focused on providing IBM i security solutions. Carol has over 30 years’ experience with IBM i security, starting her career as Security Team Leader and Chief Engineering Manager for iSeries Security at IBM in Rochester, MN. Since leaving IBM, she has co-founded two companies: SkyView Partners and DXR Security. Her practical experience and her intimate knowledge of the system combine for a unique viewpoint and experience level that cannot be matched.
Carol is known worldwide as an author and award-winning speaker on security technology, specializing in IBM i security topics. She has written seven books on IBM i security, including her two current books, IBM i Security Administration and Compliance, 3rd Edition and Mastering IBM i Security, A Modern, Step-by-Step Approach. Carol has been named an IBM Champion since 2018 and holds her CISSP and CRISC security certifications.
MC Press books written by Carol Woodbury available now on the MC Press Bookstore.
 |
IBM i Security Administration and Compliance: Third Edition Don't miss the newest edition by the industry’s #1 IBM i security expert. List Price $71.95 Now On Sale
|
|
 |
Mastering IBM i Security Get the must-have guide by the industry’s #1 security authority. List Price $49.95 Now On Sale
|
|




 More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment.
More than ever, there is a demand for IT to deliver innovation. Your IBM i has been an essential part of your business operations for years. However, your organization may struggle to maintain the current system and implement new projects. The thousands of customers we've worked with and surveyed state that expectations regarding the digital footprint and vision of the company are not aligned with the current IT environment. TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now.
TRY the one package that solves all your document design and printing challenges on all your platforms. Produce bar code labels, electronic forms, ad hoc reports, and RFID tags – without programming! MarkMagic is the only document design and print solution that combines report writing, WYSIWYG label and forms design, and conditional printing in one integrated product. Make sure your data survives when catastrophe hits. Request your trial now! Request Now. Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works.
Forms of ransomware has been around for over 30 years, and with more and more organizations suffering attacks each year, it continues to endure. What has made ransomware such a durable threat and what is the best way to combat it? In order to prevent ransomware, organizations must first understand how it works. Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include:
Disaster protection is vital to every business. Yet, it often consists of patched together procedures that are prone to error. From automatic backups to data encryption to media management, Robot automates the routine (yet often complex) tasks of iSeries backup and recovery, saving you time and money and making the process safer and more reliable. Automate your backups with the Robot Backup and Recovery Solution. Key features include: Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online