








Avoid common SQL programming mistakes that can change your query speed from a cheetah to a tortoise.
This tip continues the series started in Part 1 that discusses some common SQL coding styles that can be improved. While some examples may seem trivial, under a heavy load, saving CPU cycles and reducing data and journaling I/O can make a considerable impact on overall system performance.
Join Correlation with Inconsistent Data Types
Often there is a need to join data in tables on columns with incompatible data types, especially on systems that have applications written by different individuals or vendors. A common example is having an employee ID defined as DECIMAL(5,0) in an Employee table and the same ID defined as CHAR(9) in a transaction table (from another application).
In this situation, the following approach is common (the example assumes character column TransEmpNo contains valid decimal data):
SELECT *
FROM Transaction T
JOIN Employee e ON CHAR(e.EmployeeId)=p.TransEmpNo
WHERE T.TranDate BETWEEN @StartDate AND @EndDate;
Considering that the Employee table will likely be considered as the secondary table in the join order by DB2 (with a primary key on EmployeeId), the CHAR function will force DB2 to convert the EmployeeId column to character and thereby eliminate its ability to use the primary key. The correct way to code is to cast the character TransEmpNo column to DEC(5,0) so that DB2 can take advantage of the primary key on the Employee table.
SELECT *
FROM Transaction T
JOIN Employee e ON e.EmployeeId=DEC(p.TransEmpNo,5,0)
WHERE T.TranDate BETWEEN @StartDate AND @EndDate;
Since V5R3, the JOIN can be done without an explicit cast one way or the other; however, DB2 will follow the rules for implicit CASTing and may choose the suboptimal CAST.
It’s easy to see the significant difference in the plans built by DB2:
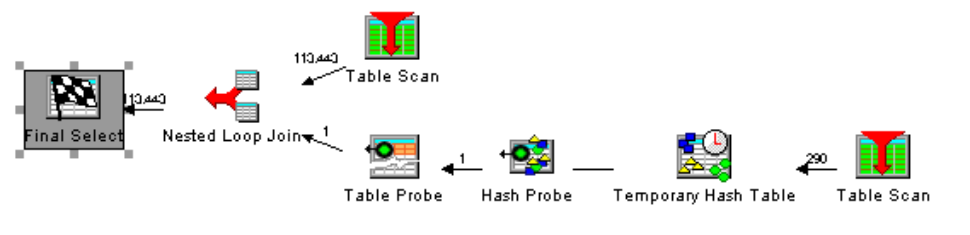
Figure 1a: Query with the CHAR cast applied to the decimal employee ID
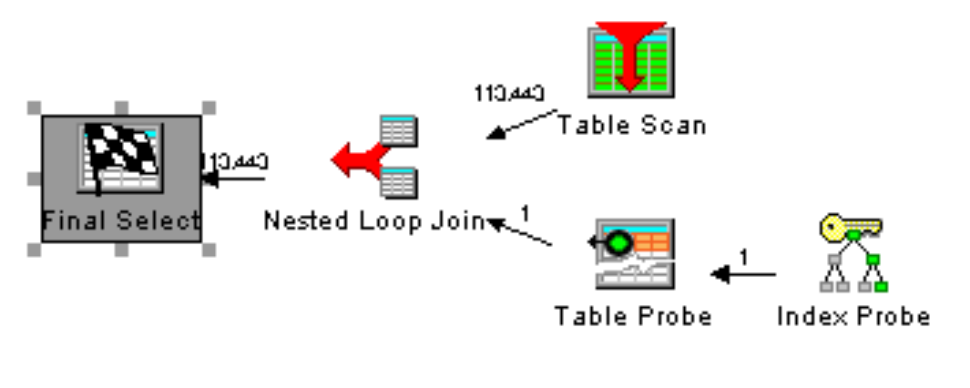
Figure 1b: Query with the DECIMAL cast applied to the character employee ID
The one unfortunate case where the first query may be appropriate is when the TransEmpNo column contains strings that cannot be converted to a number (such as if it contains alphabetic characters). In that scenario, the second query would cause DB2 to choke because it cannot cast the data.
Use Care When Using Expressions in Predicates
A principle for SQL coding is to avoid using unnecessary expressions with columns that may be important to DB2 for index access or statistics. Index access is very important as it allows DB2 a shortcut to retrieve specific data without having to read the entire table. While not as important for performance as indexes, statistics help DB2 estimate how many rows a query might retrieve when it analyzes the query predicates. Accurate row count is important as it helps DB2 choose the join order of tables and allocate memory for the anticipated data volume.
Consider the SALESORDERDETAIL table, which has an index built on column ProductId. The following query, because of the COALESCE function, is suboptimal:
SELECT COUNT(*)
INTO @ProductCount
FROM SalesOrderDetail
WHERE COALESCE(ProductId,0)=@ProductId;
In this case, use of the COALESCE function prevents DB2 for i from using the available ProductId index, thereby causing DB2 to read the entire table. Many developers think the COALESCE function should be used to process a nullable column. However, DB2 works fine without it. If the application needs a count of rows where ProductId contains a NULL, then a separate query with a ProductId IS NULL predicate is appropriate.
For another simple example where using expressions can cause a performance problem, consider a sales order header table with an index on column OrderDate. When writing a query to get orders from the past two years, sometimes developers write code like this:
SELECT COUNT(*)
FROM SalesOrderHeaderEnlarged
WHERE OrderDate+2 YEARS>=CURRENT_DATE
Code like this just makes me go all to pieces. Using date math on the OrderDate column prevents DB2 from effectively using the index on this column. The correct way to code this is:
SELECT COUNT(*)
FROM SalesOrderHeaderEnlarged
WHERE OrderDate>=CURRENT_DATE-2 YEARS
The query plans look similar as they both use the OrderDate index for the simple query:
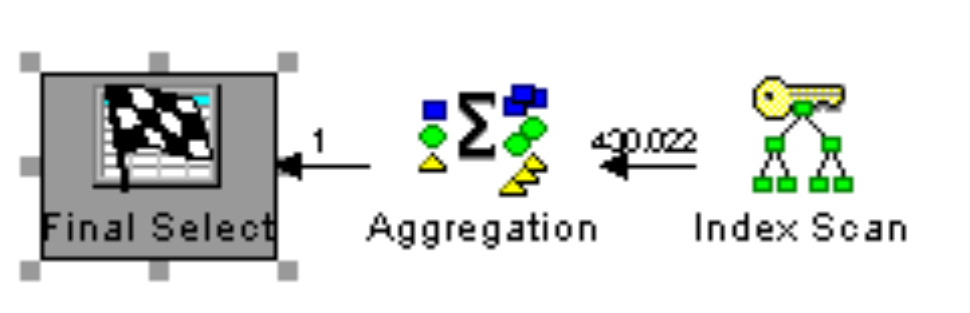
Figure 2a: WHERE predicate contains an expression on ORDERDATE column (suboptimal)
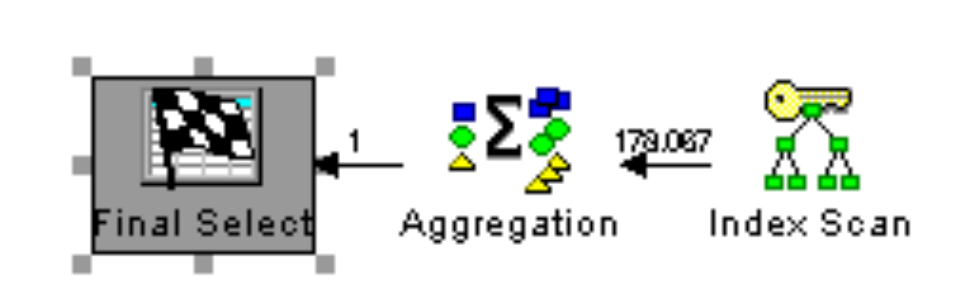
Figure 2b: WHERE predicate contains an expression on CURRENT_DATE special register (optimal)
Even though the operators are the same, the rows processed in the index scan are different. It turns out the second query ran about 20 percent faster during my testing. It’s possible that, in a future version of DB2 for i, the query engine will be smart enough to automatically rewrite the suboptimal ORDER_DATE predicate in the first example to match the second example.
For a final example, consider this search against the SalesOrderHeader table against indexed character column CREDITCARDAPPROVALCODE:
SELECT *
FROM SalesOrderHeader
WHERE TRIM(CREDITCARDAPPROVALCODE)='55680Vi53503';
The TRIM function in this example removes leading and trailing spaces before doing the comparison (but preventing DB2 from using the column’s index). I see developers using this type of defensive code because they’re trying to make sure nothing slips through the cracks.
If column CREDITCARDAPPROVALCODE is fixed width or contains trailing spaces, you don’t need to worry about trimming as DB2 automatically ignores trailing spaces when doing string comparisons. If there are leading spaces in this type of column, it is probably bad data that should be fixed (along with the code that allowed it in the database).
Incidentally, CHECK constraints should be used to prevent bad data from getting into the table in the first place (so queries won’t have to check for these kinds of invalid data conditions). Also, in languages like C# and Java, trailing spaces are not ignored when doing string comparisons, which makes developers assume database code is written the same way. However, unnecessary defensive DB2 code like this can slow down a query.
While normally I do not advocate using a function in a predicate, there are some exceptions. For example, in the following code example, the SUBSTRING search performs as well as the LIKE:
SELECT *
FROM SALESORDERDETAIL d
WHERE CARRIERTRACKINGNUMBER LIKE '4E%'
SELECT *
FROM SALESORDERDETAIL d
WHERE SUBSTRING(CARRIERTRACKINGNUMBER,1,2)='4E'
NOTE: Visual Explain’s (actual runtime ms) consistently showed the SUBSTRING version edging out the LIKE version in performance. However, in the analysis of the same SQL statement using the monitor “show statements,” the average and run time columns showed the two statements as equals in performance (judged by statement duration). I’m not sure why that discrepancy exists between the two tools.
The only way to check whether or not DB2 for i is smart enough to allow for an expression on a column in a predicate is to test.
Finally, the benefit of this coding tip applies to columns that provide the primary filter criteria for a query. If other predicates in a query do the majority of the WHERE/JOIN filtering, then the impact is lessened when using an expression on a column that doesn’t do much filtering.
No Speed Limit
This tip demonstrated that care should be taken when joining data with different data types and when using expressions on columns in a predicate. Incorrect coding can prevent DB2 from using an available index. Further, an expression that unnecessarily masks a column comparison due to an expression (such as in the TRIM example) may prevent DB2 from using statistics on the column, potentially leading to a suboptimal cardinality estimate, which in turn can lead to an inefficient access plan.
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online