








Actually, this first look is actually a look into the future!
In the previous article, I showed you how to create a fully functional, working DB2 environment on your PC for no cost. It's a little unusual for many of us: DB2 10.1 running on a Linux appliance inside of Oracle VirtualBox! Our familiarity with PCs may not extend much past Windows, but I've created an environment that seems about as foreign to the IBM midrange as it can get. Yet this odd little environment running in a little Linux bubble on my desktop has one really powerful capability: it can show me the future!
And No, Not with a Crystal Ball
So how did I manage this feat of legerdemain? It starts with the data—or more precisely, the database software. While we know our beloved database as "the database," the world outside first knew it as DB2. Originally designed for mainframes, DB2 was also incorporated under the covers in the midrange, which is how we RPG programmers came to know it. At the other end of the spectrum, IBM's entry into the PC world, OS/2, had a database management system that was fast becoming unmaintainable. Seeing the writing on the wall, IBM decided to merge everything into a single vision of DB2, known as DB2 UDB (or universal database). Once IBM committed to the concept, something interesting happened: the version for the commodity hardware, dubbed DB2 for LUW (Linux, UNIX, and Windows) took over as the primary development vehicle. Enhancements that push the edge of database technology now show up in the LUW version first and then gradually make their way back to the mainframe and midrange products. And that's how we can see the future: features in the current DB2 LUW versions foreshadow features that will end up in the other platforms. At least we hope so!
With that in mind, I'd like to give you a glimpse into what we hope the future will hold for the IBM i in an upcoming release.
Welcome to pureXML
We already have rudimentary support for XML on the IBM i today: you can define a column of type XML in your database. While in itself it's not very useful, it does at least imply that IBM intends to provide more XML support in the future. Given IBM's commitment to a single universal database, our little DB2 LUW appliance will allow us to get an idea of just what that support will look like. So welcome to the future; welcome to pureXML!
As it turns out, the appliance as supplied from IBM has some excellent example data in it. Probably the simplest file to work with is the CUSTOMER file. It has a customer ID and an XML document that describes the customer, along with an XML history field, which is unused. A simple query of the data looks like this:
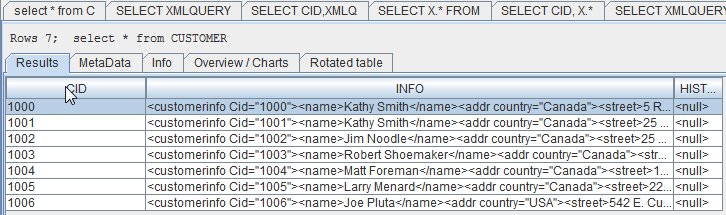
Figure 1: A simple dump of the CUSTOMER table shows the relational and XML fields.
I'll mention a couple of things. First, this is almost entirely the IBM test data that was included with the appliance, with the exception of the inclusion of my own row. That's why you'll see a lot of Canadian data; DB2 is developed in the Toronto labs. But that means you have good working data to start with, something you don't get from a scratch install. That's another great benefit of a preconfigured appliance. Second, you may recognize the interface. It's SQuirreL SQL running in Windows, although it will run in whatever operating system you prefer. That means you don't have to even touch the Linux environment except to start it and stop it. As you can see, the file has three fields in it: CID, INFO, and HISTORY. CID is a normal numeric field, while INFO and HISTORY are XML fields.
OK, up until now all we've got is a data file that has a bunch of text data in it. The data is formatted as XML to be sure, but to standard SQL it's still text data and not something we're used to using in any sort of programming environment. But that's where pureXML comes into play. This article gives you just a brief introduction to these new capabilities, so check back for more installments as we really begin to see what's available in the world of XML and relational data.
First, let's just grab some data out of the file. Let's just show the name.
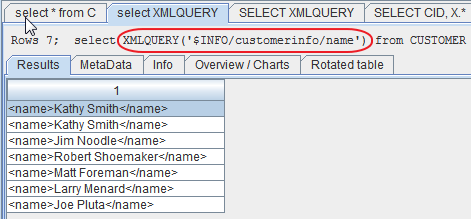
Figure 2: The highlighted statement shows an example of DB2's XQuery interface.
DB2's implementation of the XQuery syntax is pretty straightforward. It uses the keyword XMLQUERY: select XMLQUERY('$XMLFieldname/path to the data') from TABLE. I highlighted the XMLQUERY clause in Figure 2. The first segment of the parameter to XMLQUERY is the name of the field preceded by a dollar sign. We're parsing the INFO field. The rest of the statement is the path within that field to the desired element. To see how that works, let's take a quick peek at the entire XML for the row I added.
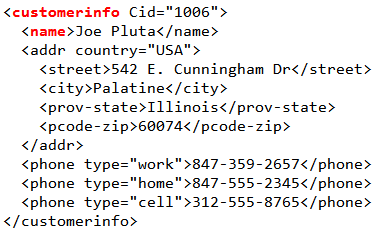
Figure 3: This is the data from my row, with the tag path highlighted.
So the XMLQUERY directs DB2 to parse the INFO field, find the customerinfo tag, and then find the name tag within that and return the contents. As you can see, it returns the values enclosed in a tag, and in fact the data is returned as type XML, not a CHAR. So really you can't yet use it. There's a way to convert these XML bits into data, but first let's see how we can limit the data.

Figure 4: The XMLEXISTS function is used to test values within the XML.
What we see here is a simple filter by country. All you have to know is where in the XML document the country value resides. In this case, the value is an attribute (not a tag) named country, which is part of the addr tag.

Figure 5: This is the path to the country value.
I've once again highlighted the path through my row. As long as your XML is built sensibly, you should have no problem finding the correct data. As I said, this is just barely scratching the surface. We still have to turn the data into a form that's usable in a relational environment, both to join to other tables and to be returned to our programs. We also have to learn about iterating through data with tags that have multiple instances. Those things will be covered in more depth in subsequent articles. For now, have fun with the DB2 10.1 appliance you've installed and take a look into the future!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online