








The first step of the journey from OPM to ILE is getting a grasp on the foundational concepts of ILE. This TechTip explains how the module, program, and service program concepts relate to OPM's program concept.
How do you create an OPM RPG program? You write your source, compile it with PDM's option 14, and (after you squashed all those annoying little bugs) you get a *PGM object. To create an ILE program, the steps are similar: you compile your source not into a program, but into a module, and then you create your program. But, if it's the same source, why the additional step of creating a module? Well, to explain that, we need to go back to the previous TechTip, to the part that mentions that two of the main advantages of ILE are modularity and reusability.
The typical OPM RPG program is an all-in-one block of code: it contains a group of subroutines to handle the screen (if the program has one), another group to handle the necessary validations, and, if things are really well organized, a subroutine or two to handle the database interactions. The problem is that some of that code probably exists in some other program—even if the program's purpose is different, the validations or the database interactions are probably the same or at least similar. Let me give you an example. Figure 1 shows a typical OPM scenario:
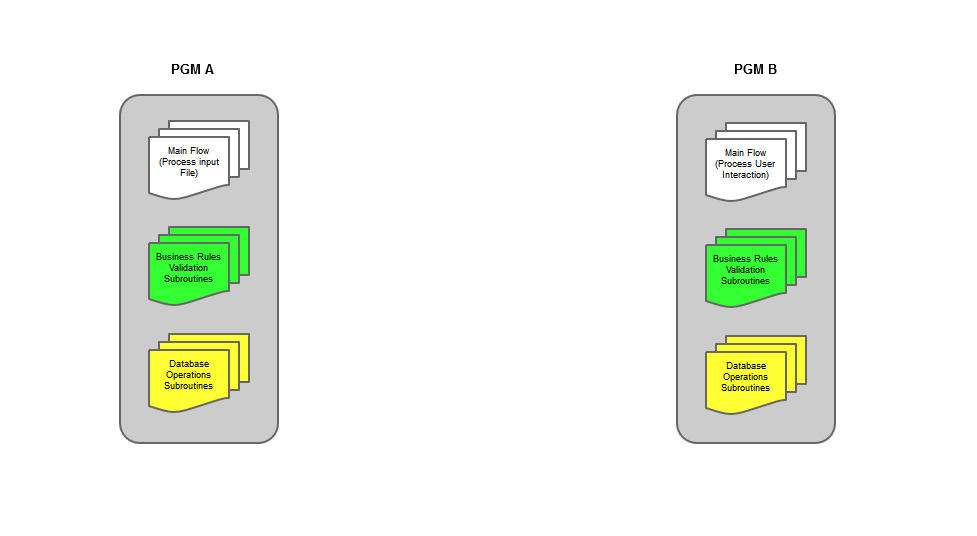
Figure 1: This OPM scenario shows two programs that have some duplicated code.
PGM A is used to enter items into the company's inventory automatically, using the cargo manifest of an inbound shipment. This is a fixed-format text file that contains all the relevant information for the inventory. PGM B is used to manage the inventory interactively; it allows the user to add, change, and remove items from the inventory. Both programs will have some code that is similar (sometimes, an exact copy of subroutines) to handle the business rules related with inventory management (group of subroutines depicted in green) and with the respective DB operations (group of subroutines depicted in yellow). If the programs' functionality is different, the two groups of subroutines won't be exactly the same, but they'll probably have a lot in common.
That's where ILE's modularity comes into play. By isolating those similar sets of code (hopefully, they're already self-contained in subroutines) into procedures (that's a concept that I'll detail in the third TechTip of this series; for the moment, think of them as subroutines with parameters) and grouping those procedures in modules, we can easily re-use the modules in different programs. The basic ILE approach to this inventory programs scenario is shown in Figure 2:
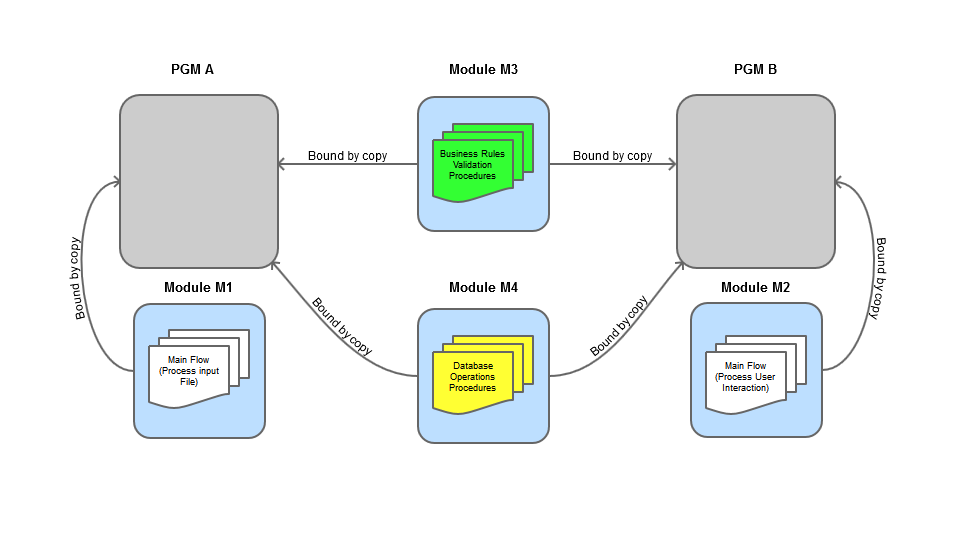
Figure 2: This basic ILE scenario shows four modules, bound by copy to the two programs.
It would require creating four modules: one for each of the program flows (PGM A's loop through the cargo manifest file is Module M1, and PGM B's loop through user interaction is M2), one for all the business rules-related code (M3), and finally the last for the DB operations (M4). Note that the "Main Flow" modules (M1 and M2) only have the code that acts as the backbone of the programs, guiding their flow. Everything else, even if it was not duplicated, was isolated into procedures and placed in M3 or M4, depending on its nature. By doing this segregation, you assure that future programs related with inventory can re-use these blocks of code.
This re-usability likens RPG to more "modern" languages like Java or PHP. Then all you have to do is create the programs using the modules as building blocks, because *MODULE objects cannot be executed. Note that the modules can be built using one of the several ILE languages available: a *PGM object can be composed of RPG, C, C++, or COBOL modules, as long as the procedures contained in them are able to "talk" to one another.
What do we know so far? A *PGM object is composed of one or more *MODULE objects. Modules are not executable; programs are. How are programs and modules linked? Well, when you create a program, you need to indicate which modules are going to be part of that program and, of those modules, which will be the entry point, or the first to be executed, to get the program running. Going back to our inventory scenario, PGM A would have three modules (cargo manifest file flow, business validations, and DB operations—respectively, M1, M3, and M4), and M1 would be the entry module. The same goes for PGM B, replacing M1 by M2. The problem here is that programs are created by copying the modules. This means that you'd be duplicating the business rules and DB operations modules. Note that you won't actually see this duplication; it happens on the *PGM object's creation, increasing each program's size. This approach also has another problem: any change to the business rules or DB operations modules would require all the programs that used them to be recreated! This doesn't seem very practical, right?
That's where the service program concept makes its appearance. A *SRVPGM object is another way to group *MODULE objects. It solves the two problems I mentioned before: by linking the modules to a service program instead of linking them directly to each of the programs and then linking the service program to PGM A and PGM B, you get the same functionality and code separation without the duplication of code and, up to a certain extent (I'll explain this "certain extent" on the next TechTip, I promise), you're also able to eliminate the need for program re-creation every time a line of code is changed on the modules, because the service program is not bound by copy, but by reference, to the programs. Figure 3 shows this scenario:
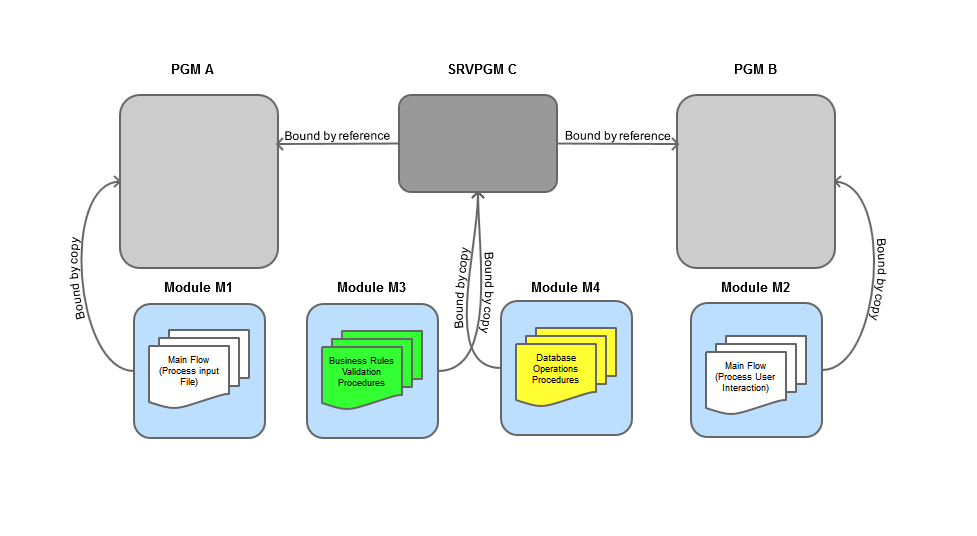
Figure 3: Implement the same functionality with a service program.
Of course, changes to M1 or M2 will still require the programs to be recreated because those modules are still bound by copy to the respective programs. A service program is like a collection of runnable procedures, ready to be used in programs or other service programs. A service program, like the modules bound to it, cannot be executed. The great advantage here is, as long as you don't change certain characteristics of the service program, you are free to change the code of its modules without recreating all the programs that are bound to that service program. However, whenever you change a module that's bound to a service program, it's a good idea to recreate the service program, because even though it might not produce an error, it might lead to baffling decimal data errors and other strange errors that are difficult to trace on the programs that use that service program.
Let's finish with a quick summary of these concepts:
- *MODULE—Contains one or more procedures; cannot be executed.
- *PGM—Composed of one or more modules; these modules can be built on different languages; *PGM objects can be executed; the simplest (and most similar to OPM) form of an ILE PGM is having just one module that contains all the necessary code for the program's functionality (possible, even though not advisable, because it doesn't take advantage of ILE's modularity and reusability).
- *SRVPGM—Composed of one or more modules; cannot be executed; allows modules to be reused without being duplicated in each program; a certain level of change to a module is possible without changing the programs that use the service program to which the module is bound; however, it's advisable to recreate the service program every time one of its modules is changed.
In the next RPG Academy TechTip, I'll explain how this "binding" between modules, service programs, and programs works and give you a quick tour of the commands to create each of these system objects.

Rafael Victória-Pereira has more than 20 years of IBM i experience as a programmer, analyst, and manager. Over that period, he has been an active voice in the IBM i community, encouraging and helping programmers transition to ILE and free-format RPG. Rafael has written more than 100 technical articles about topics ranging from interfaces (the topic for his first book, Flexible Input, Dazzling Output with IBM i) to modern RPG and SQL in his popular RPG Academy and SQL 101 series on mcpressonline.com and in his books Evolve Your RPG Coding and SQL for IBM i: A Database Modernization Guide. Rafael writes in an easy-to-read, practical style that is highly popular with his audience of IBM technology professionals.
Rafael is the Deputy IT Director - Infrastructures and Services at the Luis Simões Group in Portugal. His areas of expertise include programming in the IBM i native languages (RPG, CL, and DB2 SQL) and in "modern" programming languages, such as Java, C#, and Python, as well as project management and consultancy.
MC Press books written by Rafael Victória-Pereira available now on the MC Press Bookstore.
 |
Evolve Your RPG Coding: Move from OPM to ILE...and Beyond Transition to modern RPG programming with this step-by-step guide through ILE and free-format RPG, SQL, and modernization techniques. List Price $79.95 Now On Sale
|
|
 |
Flexible Input, Dazzling Output with IBM i Uncover easier, more flexible ways to get data into your system, plus some methods for exporting and presenting the vital business data it contains. Now On Sale
|
|
 |
SQL for IBM i: A Database Modernization Guide Learn how to use SQL’s capabilities to modernize and enhance your IBM i database. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online