








I try to use SQL wherever it makes my programs better, and here's a great example of using it to enhance your inquiries.
By this time, nearly everyone who programs in RPG has at least heard of embedded SQL. No matter what version of RPG you're using, you have an opportunity to take advantage of this fantastic tool that extends the RPG language in a way that most other languages just don't get. The embedded SQL support for RPG allows me to write SQL statements that interact directly and seamlessly with host variables, something I wish could do in my Java programming. This close cooperation lets you easily take advantage of the capabilities of SQL in your everyday RPG programs. Let me show you how SQL can enhance your subfile inquiries.
Order and Selection
Recall what SQL stands for: Structured Query Language. Originally, SQL was primarily a query language and we used other techniques to modify our data, most often some form of indexed sequential access method (ISAM ) like the one built into the IBM i (now known as DB2 for i). Over the years, a lot of functionality has been added to SQL to bring it closer to ISAM as a business application database management tool as well as a business intelligence engine. That sometimes overshadows one of SQL's primary strengths: selecting and ordering data. If you want to be able to dynamically select and sort data, SQL is hands down the best tool out there. Today, I'm going to go back to old-school SQL and show you how it can be used to pump up your subfiles.
Standard Subfile Processing
Traditional inquiry subfiles display a list of records, usually with some options. Sounds simple, but even this simple statement includes several implicit assumptions. For example, which data is selected and in what order? Selection includes both rows and columns, and order can be a single field or a combination of many values. Let's take a more concrete example. Let's display the item master file. A simple inquiry might look like Figure 1.
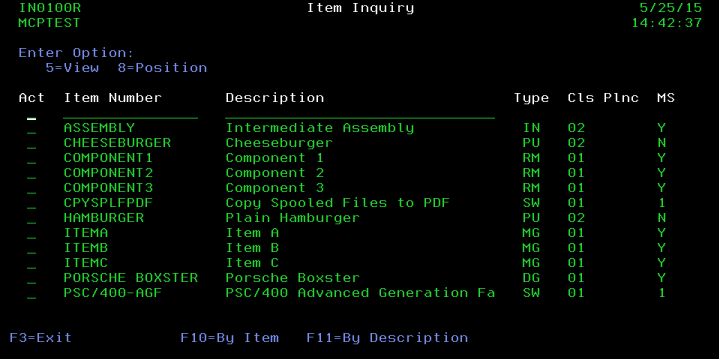
Figure 1: A standard inquiry has one or more sequences and usually some positioning fields as well.
Let's review some of the underlying assumptions here. First, we've got only two sequences: item number and item description. Second, we can position based on whichever sequence we're in. In order to do this using native I/O (also known as Record Level Access, or RLA), we have to create the appropriate objects. We need the physical file, and we need two logical files, one each by item number and by description. A discussion can be had as to whether the physical file can be keyed by the primary key, thus eliminating the need for one of the logical files, but that's somewhat immaterial; we still need the access path. If we were to build this same inquiry using SQL, we would probably have the same basic building blocks. In SQL parlance, we'd have a table with a primary key (roughly equivalent to a keyed physical) and an additional index by description. One big difference exists between RLA and SQL: the index by description is optional. Even if it didn't exist, we'd still be able to query the data in description order. The program just wouldn't perform as well since the system would have to build the index on demand.
But let's say we built the objects as I described; why would we want to use an SQL approach rather than an RLA approach? In RLA, we simply have to define the file on an F-spec and then use simple SETLL and READ opcodes to get the data. For multiple views, we just add more logical files to the program and read the appropriate one. With SQL, we have to define a cursor, identify the fields we want to bring in, open and close the cursor, write FETCH statements; it really is quite a bit more work and can be tedious, especially defining the individual fields. You can use externally defined data structures to reduce the tedium, but that locks you into the table (file) definition, which negates one of the major advantages of SQL. But I'm going to leave that lie for now; table independence is another topic for another day.
What I want to focus on is the flexibility of the query. Figure 1 shows the item number and description fields. These are usually position-to fields, which allow the user to position the view based on what they enter into the field. One of the first requests I usually get with this design is for the ability to use wildcards on the positioning fields. Wildcards in RPG aren't particularly easy unless you only allow a wildcard at the end of the field (which if you think about it isn't really much better than a position-to field). There are Regex (regular expression) APIs available, but they're neither simple nor intuitive. I want the user to simply be able to use something like *burg* to get hamburger or cheeseburger, and I don't want to learn about compiling and executing regular expressions. SQL to the rescue!
By taking advantage of the LIKE predicate in SQL and one of my favorite BIFS, %scanrpl, I can easily implement a wildcard approach. Let's take a look.
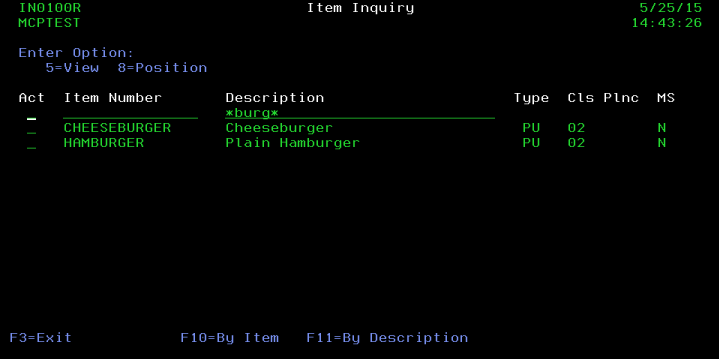
Figure 2: A great benefit for users is to implement wildcards for searching.
In Figure 2, I enabled wildcards in the description field. The logic is actually quite simple: if the position-to field has an asterisk, replace any asterisks with percent signs (because SQL uses a percent sign as its wildcard token) and then use the LIKE predicate. Otherwise, just use the field as a normal position-to field. The code might look something like this:

Figure 3: This cursor allows us to either position by or scan for a wildcard in a field.
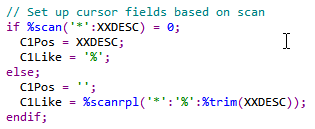
Figure 4: This code sets the cursor fields, setting one to a default value and the other to do the actual work.
Figures 3 and 4 show how the code can be written. The SQL cursor is set up to both position and scan the file based on the same field (in this case, IMDESC, the item description field). The RPG logic then checks the field from the screen (XXDESC) to see if the user entered a wildcard. If the %scan BIF returns 0, the user didn't enter an asterisk, so the logic places the user input into the position-to field and sets the target of the LIKE clause to the all-inclusive value "%". This is a lot of work to emulate an RPG SETLL, but that's what it does! However, the other lines are what perform the real magic. If an asterisk is found, the program sets the position-to field to the low value of blanks, and then sets the like field to the result of the %scanrpl BIF. In our example above, the C1Like field would contain "%burg%" which then includes every item with "burg" in the description.
You probably noticed the generous use of UPPER in the SQL statement; that's only necessary if your scanned field allows lowercase and then only if you want the wildcard logic to be case-insensitive. There are some other tricks that can be used when dealing with case, but for now this should get you moving. The big thing to take away from this is that the positioning field is now not only enabled, but context-sensitive; if the program sees that the user meant to use a wildcard, it modifies its behavior accordingly. This tends to make users' lives easier, although you should be careful not to make the program logic vary too widely; that can confuse users.
I hope you can take advantage of this technique in your programs. I'll be covering more ways to integrate SQL into your green-screen programs in future articles. And as you might expect, any of these techniques can also help you with your thin- and thick-client applications as well!

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online