








A robust enterprise architecture requires a flexible environment; this article shows you how to configure one.
Sometimes the simplest things are the most effective. In my career in information systems, I've found powerful simplicity to be the hallmark of the most sophisticated computer software. The concept of a hardware interrupt is a great example: the voltage on a pin goes high and magic occurs. This simple technique is the basis for nearly every multi-tasking operating system ever written. We midrange developers are lucky to have many such architectural treasures in our favorite operating system, and this article focuses on one of the most powerful: the library list.
Doesn't Everyone Have a Library List?
You'd think so, but the truth is that the library list is a uniquely midrange concept. Since the IBM midrange platform has from its origins been object based, that means that every QSYS object we use belongs to a library. (Note that I qualified the statement to include only QSYS objects; other objects—such as those in the IFS—do not fall within these same rules.) Because every object, from a data file to a program to an output queue to a message file, comes from a library, the library list can cause every object used by that job to come from a library appropriate to that environment.
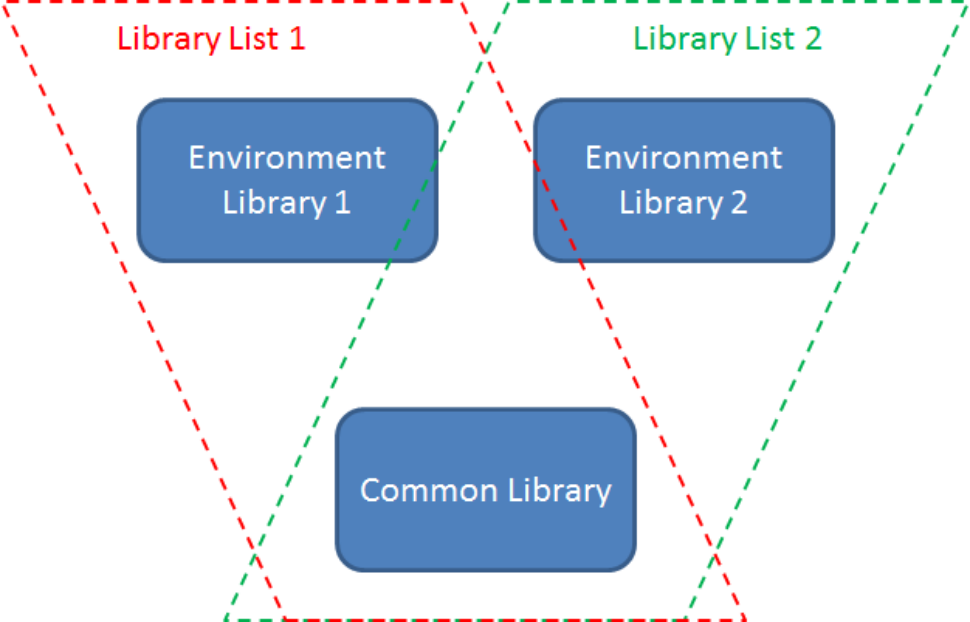
Figure 1: These two library lists share some common objects.
Many operating systems have a similar concept, but the implementation is usually incomplete and fragmented. For example, Windows has a path environment variable that’s used to look up programs, but it doesn't help with database files. Only the IBM i allows you to use this concept for every part of your program.
Using the Library List to Identify Your Environment
While Figure 1 is a very simplified example of a library list configuration, it is entirely adequate to illustrate how the library list works. Let's take a standard business requirement of having two environments: one for test and one for production. Let's say environment 1 is the production environment. In that case, production data would be in that environment library 1, while a separate copy of test data would be in environment library 2. All the programs reside in the common library. This way, you can make changes in your data setup without affecting production. (This is also often accomplished by having separate partitions, but with a library list you don't have to have that additional overhead.) You can also use this setup to test program changes, either by putting test programs into environment library 2 or by having an additional test program library that you add to library list 2.
Library lists work with any environment requirement. Some applications don't support, for instance, multiple companies. In that case, you'll need a separate data library for each company. The environment libraries contain the company-specific data, but the common library contains all the program objects. We could come up with a dozen different scenarios where library lists can be used for environmental support, ranging from security to multi-language support to vendor upgrades. The library list is a phenomenally powerful feature.
Getting Your Initial Library List
This is where things get tricky. It's not that the IBM i makes it difficult to configure your library list. To the contrary, there are many ways to get to an initial library list, so many that the correct one is not always intuitively obvious. I'll give you several techniques. To start, interactive jobs almost always have some sort of configuration built into their startup menu. When users sign on, they typically get a menu and that menu sets up their library list. The library list itself is usually configured in a database file, with varying degrees of complexity. Some users can even switch between environments using a menu option or a utility. And almost always, there is a program that can call with the appropriate parameters and get a new library list. Remember that, because we'll return to the concept a little later.
So really, the interactive programs aren't the hard ones (although switching between environments can require a little work). The harder part is when you need to set up the initial library list for a batch job. And even that isn't terribly difficult except in one specific case, which we'll get to in a moment. But first let me cover the library list issue for batch jobs submitted from interactive jobs. In that case, your best bet is simply to use the library list of the interactive job, which you can do by specifying the keyword INLLIBL(*CURRENT) on the SBMJOB command. This probably should be your default setting on any submitted job; it's a rare case when you would want to submit a job with a library list other than the one you're currently using. That would be like submitting a job for production out of test. That's not to say it will never happen; you might have nightly jobs that you run and you'd like to have a single utility job submit the nightly jobs for each company. But for the vast majority of cases, you're going to use the current library list.
But what do you do when you have no initial interactive job? The typical case is when you're running an auto-start job. These jobs run in the background and handle asynchronous tasks. They can do anything from handling long-running batch reports to monitoring for system events. One of my most common uses is to monitor the IFS: users map a drive to the IFS and then simply copy a file into it. A batch IFS monitor job sees the new file and uploads it as appropriate. This can automate a whole lot of external data uploads, but how do we know which environment the job is running in?
To explain it, I'll have to run through a quick explanation of subsystems and autostart jobs. While there are many different configuration values for subsystems and job descriptions, there are only a few that are relevant to the concept of autostart jobs. Setting up an autostart can seem a little convoluted but only because it allows so much configurability. I'll give you a very specific setup style. We're talking about having two environments: environment 1 and environment 2. Environment 1 uses libraries ENV1 and COMMON; environment 2 uses ENV2 and COMMON. We're going to set up a subsystem where jobs submitted there will run in environment 1. Here are the commands:
- CRTSBSD SBSD(ENV1/SBSD)
- CRTJOBD JOBD(COMMON/IFSMON) RTGDTA(IFSMON)
- ADDRTGE SBSD(ENV1/SBSD) SEQNBR(10) CMPVAL(IFSMON) PGM(ENV1/IFSMON)
- ADDAJE SBSD(ENV1/SBSD) JOB(IFSMON) JOBD(COMMON/IFSMON)
First, we create a subsystem in ENV1. I'm not going to go through all the nuances of the commands; these are just representative examples. The first command creates the subsystem. Next, we create a job description that will run our IFS monitor. The program's name is IFSMON. The second command creates a job description with the routing data "IFSMON", which becomes important shortly. The third command adds a routing entry to handle that job description. This is not necessarily intuitive, but what it says is that if a job tries to start with routing data of "IFSMON", then as its first step, call program IFSMON in ENV1. I really wish that we could pass a parameter on this statement, but we cannot. In a moment, though, you'll see how I get around that. The last step to this puzzle is to get this whole configuration to fire off when the subsystem starts. That's done by creating an autostart job entry with the fourth command. What this does is specify that when SBSD starts, the operating system should submit a job named IFSMON using the job description IFSMON. That job description has the routing data of IFSMON, which in turn means that the first program called will be IFSMON in library ENV1.
So now all we have to do is get the list of libraries for this environment from a file and then build our library list. There are two ways to do that: either use a configuration file that can be keyed by the environment name, or have separate configuration files in each environment. I tend toward the latter because cross-environment configuration can get messy. But how, then, do I point my program to the correct library? That's the key and the last bit of today's lesson:
dcl-f LIBLIST keyed extfile(wFile) usropn;
dcl-s wFile char(21);
dcl-ds *n PSDS;
psLib char(10) pos(81);
end-ds;
begsr *inzsr;
wFile = %trim(psLib) + '/LIBLIST';
open LIBLIST;
endsr;
What you see here is a simple way for an RPG program, regardless of its library list, to open a file in the library from which the program was called. The *INZSR routine will override that file to the library from which the RPG program was called (retrieved from position 81 of the program status data structure), which in this case will be library ENV1. I call this the root library because that's the root of all the other libraries: the file LIBLIST in the root library of an environment returns the list of libraries for that environment.
I could have created the job description in ENV1 and then hardcoded the library list. However, that means constant maintenance of those job descriptions. Instead, now all I have to do is call the program from the appropriate library, and the library list gets set from a file in the target library. We can use this in external jobs as well; my favorite is to call this program when setting up a connection in Rational Developer for IBM i.
I'm sure you can see other ways to do this. I've seen techniques in which the name of the job is used to provide some information. That can be cumbersome, but it will work. You can set a root library from the job name. But whatever the case, once you get your root library, you can do the rest of your library list configuration and thus have your environment set up correctly.
Caveats
The library list isn't a silver bullet. Like so many things, it has both benefits and drawbacks, and even if in my opinion the benefits overwhelmingly outweigh drawbacks, I'd be remiss to not mention them. First and foremost, the library list isn't always entirely compatible with SQL. While you can use the library list in SQL, it requires you to be a little less "SQL-like" in your approach, in particular requiring the use of the system naming conventions rather than the more standard SQL naming conventions. Life becomes even more confusing when we introduce the complexities of stored procedures. There are enough nuances here for an entire additional article (so expect to see one soon!).
I also mentioned the IFS. The IFS is much more like a UNIX or Windows environment in that you usually separate things by folders. A common requirement is having a location to put PDF versions of business documents. In our case of multiple companies, we might create folders named /PDF/Company1, /PDF/Company2, and /PDF/Company3. (Note: Another way would be to create folders /Company1/PDF and so on; please compare and contrast for extra credit.) There is no standard *LIBL concept when accessing the IFS. You may find it implemented to some degree in some special cases, such as WebSphere, but like the Windows PATH variable, it's inconsistent and incomplete. Instead, the better way is to use a standard DB2 database file configuration file. The configuration file determines the folder (or the root of an environment structure). Then, you use your library list to point you at the appropriate configuration file. Library list IFS configuration!
In the meantime, though, start thinking about how to configure your environment, especially in submitted jobs, and how root libraries can be the way to control those environments.

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online