








Concurrent Versions System (CVS) has long been a standard in the UNIX world for managing source code. Roughly 20 years old, CVS started as a bunch of scripts on top of the slightly older Revision Control System (RCS) utility. From these humble beginnings, the package has evolved into a fairly sophisticated source control tool, although it lacks some major features required for a formal change management system.
The rebranding of WebSphere Studio into the Rational line means that WDSC is now nominally based on a Rational product, so it's not surprising that it tends to push users in the direction of the Rational ClearCase tool. However, there's one really big fly in that particular ointment, one that I'll be pounding on every time I get into the subject: the Rational tools don't understand the iSeries--particularly the QSYS library system--and nobody involved with the Rational tooling seems to think that's a problem.
Because of this, there's really no way to actually manage a project that includes iSeries objects via the Rational tool suite. And if the argument is to move source code into the IFS, that still doesn't manage QSYS objects like programs and files and data areas. Not only that, but as I've mentioned before, I think IBM is missing a golden opportunity to create a language- and platform-independent IDE that would make Visual Studio look like an Etch-a-Sketch in comparison.
(Imagine this: You design a complete system--business rules, UI, everything--using a language-agnostic UML diagram. The various tiers are represented as icons. You drag the UI tier onto a JSP Model II Generator, and it automatically creates servlets and JSPs for you. You drag the business logic tier onto an RPG generator, and it writes the RPG code. Simple enterprise-level preferences identify whether to connect via Web Services or something like MQ Series. All pieces can be debugged via WDSC, and all object management is under a single tool. IBM has all the pieces to do it. Today. What am I missing?)
Today's History Lesson
I never do one of these columns without giving you a little history, and this one is no different. As I mentioned in the first paragraph, CVS was built as a set of scripts on top of RCS. RCS works with only one document at a time, while CVS was designed to support entire projects. Other issues existed that eventually separated the development path of the two utilities, such as the RCS limitation of only one person working on a document at a time. While this might seem to be a very prudent restriction (many change management systems are extensions of the basic check-in, check-out architecture), over the years it became a requirement that multiple people be able to work on the same document simultaneously. CVS allows this. In fact, the default mode of operation for CVS is "copy-modify-merge": You copy the entire repository from the server to your workstation, do your work, and then merge your changes back into the server via the commit command. CVS tries to resolve conflicts and reports anything it cannot handle.
The CVS tree has a number of branches. CVSNT is a Windows-based project that added some features (including iSeries support, although I'm not sure to what extent) and then ported the software back to Linux, UNIX, and Mac. There is also a commercial version of CVSNT. Subversion is a CVS replacement that adds a number of enhancements as well. An interesting thing about Subversion is that it has an Eclipse plug-in, so theoretically you should be able to add Subversion support directly to WDSC; this is one of the big promised advantages of the entire Eclipse strategy. To find out more about Subversion, read Barry Kline's recent column. There is also a complete online book about the tool.
The Problem with CVS
The big problem with CVS and the other packages (to a greater or lesser degree) is that they are primarily source control systems. They are designed to support a project at a source level, keeping track of revisions and so on. This wasn't originally a problem because, in the UNIX world, you often had to recompile something to get it working on your machine. Whether it was OS incompatibilities, hardware inconsistencies, or just quirks of your own particular environment, you rarely were able to simply install a binary file; often you had to recompile it to run on your machine. With the advent of open source, recompiling from source became even more prevalent, since most open source products were delivered as source code. This made the CVS source-only approach actually a reasonable way to distribute code, so object-level change management was less of an issue. Have a problem? Recompile the system!
And while later versions of the packages do now handle binary files to some degree, they are not really change management software. There are no facilities for development, testing, and production environments, nor is there any integration with automated testing or indeed anything that you would normally associate with software project management. CVS is exactly what it says it is: version control for source files.
That being said, if source control is all you need, then CVS is an excellent zero-cost entry point. For internal development, in conjunction with a good backup strategy for production data, CVS may well provide all the source control you need, at least for your J2EE development (this includes Java as well as Web components such as JSPs). In a pinch, you can probably even use it for iSeries source code; I'll talk about that a little bit later. For now, though, I'd like to show you how CVS works.
CVS and WDSC
As you probably already know, WDSC works with a concept called a "perspective." A perspective is a group of related "views," and each view is essentially a UI panel that interacts with the user to perform a specific set of tightly integrated functions. You will have multiple views in a perspective, with those views taking up various positions on the workbench. The Remote Systems Explorer (RSE) is a single view that allows you to interact with host systems, while the Debug Perspective is a group of views used to debug applications. The Console is a view that displays the output of a running application, while the CVS Repository Explorer (CRE) is a group of views used to interact with a CVS server.
It's the CRE that I'll be spending the most time on today, although there are also a few CVS enhancements to other views that integrate CVS seamlessly throughout the development process.
The CVS Repository Explorer (CRE)
To be honest, I made up the CRE acronym; I don't know that there is an "official" acronym for the CVS Repository Explorer, but CRE makes sense. In any case, this is what it looks like the first time you venture into it:
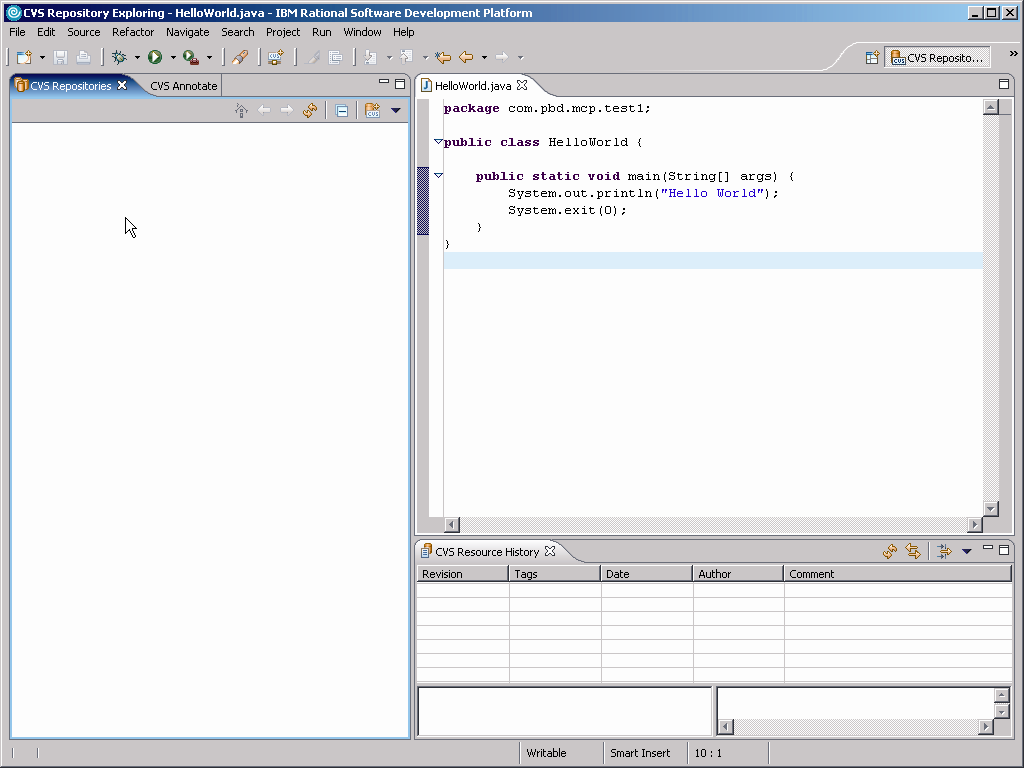
Figure 1: This is the CVS Repository Explorer perspective the first time you see it. (Click images to enlarge.)
In order to start using CVS, you need to have a CVS repository set up on a CVS server. You'll then connect to it from this perspective. Right-click inside the CVS Repositories view and select New > Repository Location... (see Figures 2 and 3).
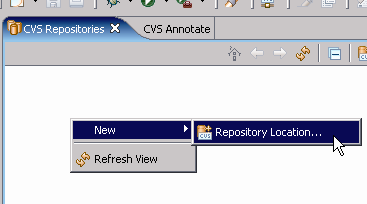
Figure 2: Create a new repository location by right-clicking in the CVS Repositories view.
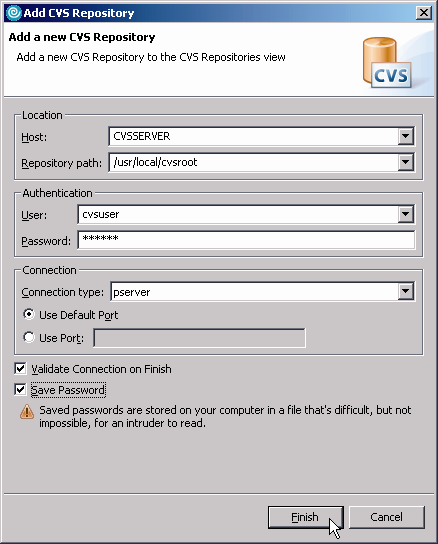
Figure 3: Fill out the Add CVS Repository wizard to add a new location.
The procedures involved in getting a CVS server running are extensively documented on the Internet and are outside the scope of the discussion here; we'll assume you have one up and running. You may already have one; your network guy (assuming that's not you!) would be the one who knows where your CVS repository is located. If you do have a repository, you'll need the following information: the host, the repository path, and the user and password. You'll also need to know the connection type and the port. Armed with that information, you can then populate the Add CVS Repository wizard and create your location.
Setting Up a Project
The next step depends on whether you already have a project in CVS or you want to create a new one. If you want to work on a project that already exists in CVS, then you would check that project out into your workspace. During the checkout process, you can either create a new project or check the source out into an existing project. In either case, remember the basic CVS philosophy of "copy-modify-merge." When you check out a project, what you've done is copy a snapshot of that project into your workspace, with the idea that at some later point you will try to check that project back in. There is nothing inherent in CVS to stop someone else from doing the same thing, and if that happens, then at some point your changes will need to be merged.
Another option is to add an existing project to the repository. It may seem like a somewhat lengthy process, but it's really quite straightforward; the wizard walks you through all the appropriate steps:
- Right-click on a project and select Team > Share Project....
- Select CVS as the repository type.
- Select a CVS repository location.
- Select a name for the project in the CVS repository.
- Review and commit the resources (files) in the project.
- Put those resources under CVS control.
- Write the check-in comment.
Once this is done, you can now start versioning. Typically, you might set this as Version 1 by right-clicking on the project and selecting Team > Tag as Version... from the menu. You can do this whenever you think you're at a logical break in your development process. Figures 4 through 6 show you the simple process.
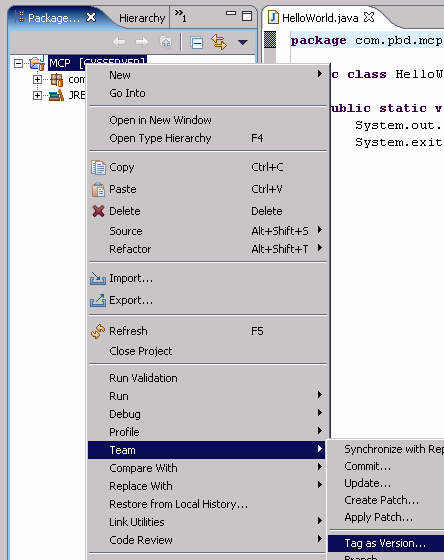
Figure 4: Right-click on a CVS project and then select Team > Tag as Version....
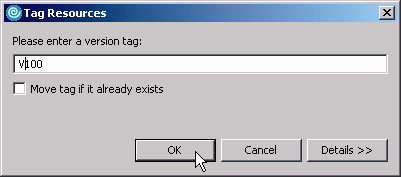
Figure 5: Type in the version number.
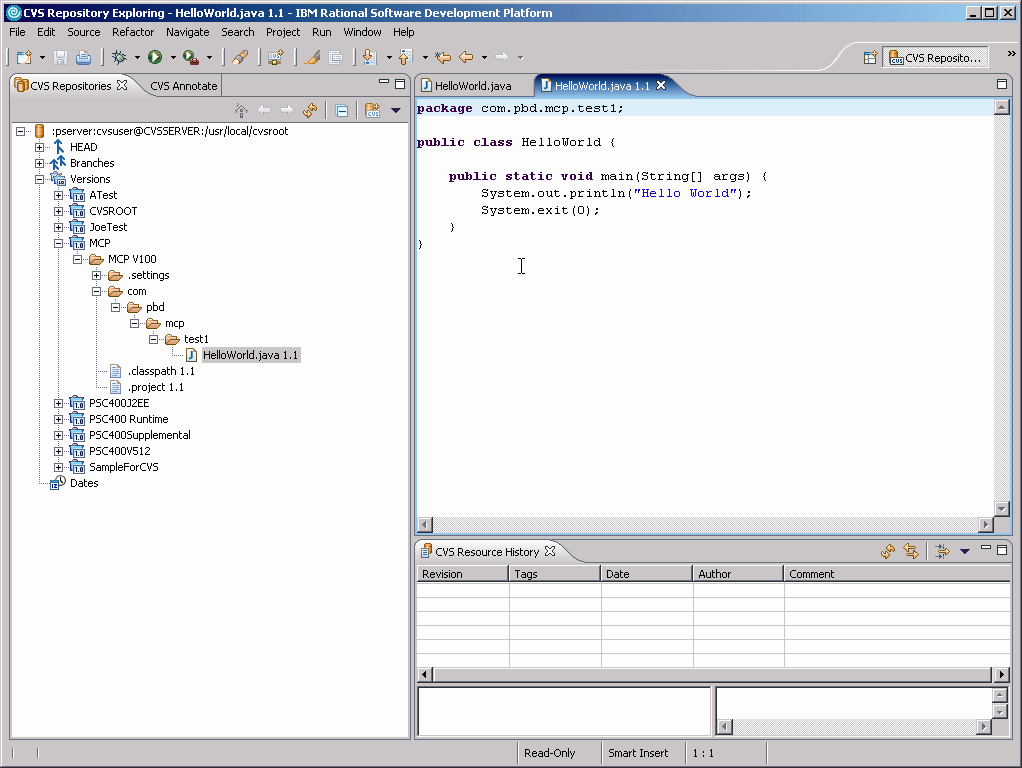
Figure 6: And now you have a versioned project!
The Benefits of Versioning
The reason behind going through all this work is to have your source code under a version control system. Why do this? Well, there are a number of reasons, starting with simple backups (since the server can be on another machine, you can even use CVS as part of your disaster recovery plan). ISVs particularly need this sort of control because it allows them to keep multiple versions of the software available, which is essential when a client calls from the blue asking for support for a five-year-old version of the software.
The thing I like to use CVS for, however, is the one thing that base Eclipse doesn't have that VisualAge for Java did have: the ability to compare current and previous versions of the software. While I don't use it often, when I do have to use it, it is absolutely essential. I'll give you a quick look at what I did.
I created a project, and in it I created the standard Hello World program. I then added the project to the repository. Finally, I tagged that project as version V100, ending with the screen you see in Figure 6.
Once that was done, it was time to do some versioning. I changed the words "Hello World" to "Hello Mother. Hello Father." and saved the changes. I committed the changes to the repository and then tagged the project again, this time as version V101. Because of this, I was then able to go into the CVS perspective and compare the two versions. The result can be seen in Figure 7.
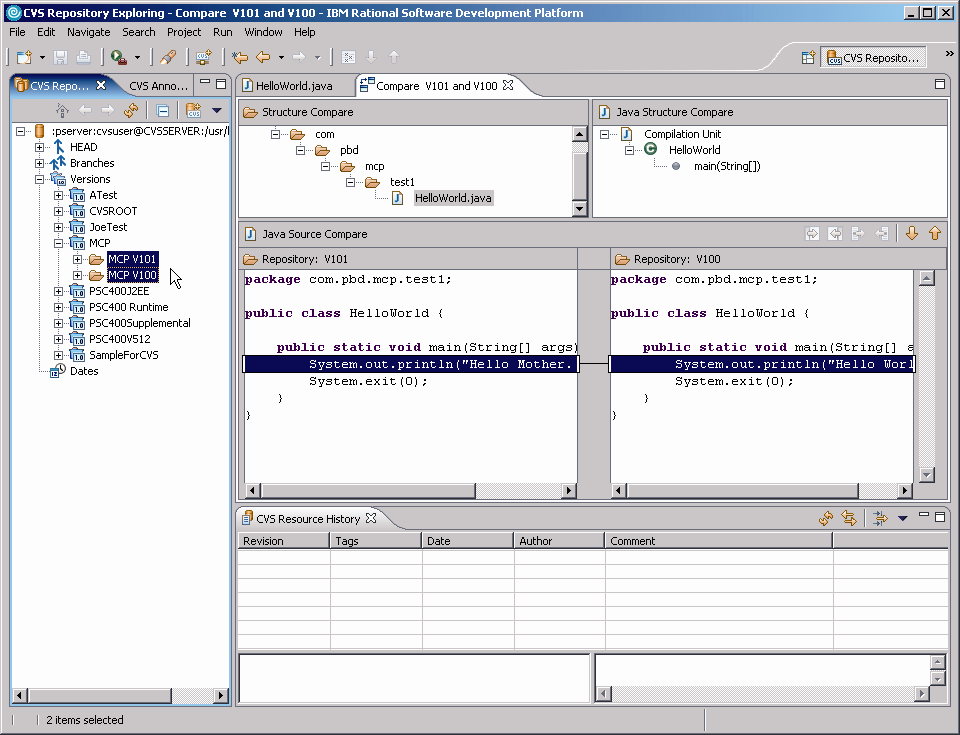
Figure 7: One great use of CVS is to compare source code between versions.
As you can see, the one line with the change is highlighted. In a typical project compare, the tool will actually compare all the files in the project and give you a list of changed files. You can then review the modifications. As I said, I don't use this often, but when it is necessary to review all changes in a project, this is definitely a fast and powerful way to do so.
Summarizing CVS
You'll note that I used Java code for testing the CVS repository functions. That's because CVS doesn't integrate directly with the QSYS library system, so it's unable to compare iSeries HLL code such as RPG and DDS. There is a workaround that involves copying the files to the IFS and then importing them into a project, but there are potential problems that need to be carefully avoided in that multi-staged architecture.
Also, CVS doesn't handle object promotion or distribution, so forget about it for shipping iSeries code. CVS is fantastic for making open source projects available to the great unwashed masses, and it works great as a source comparison utility, but for real iSeries application development project management, you'll need something a little more full-featured.
The Ongoing ISV Saga
And just to keep you apprised, the ISV struggle continues. I should have a brand spanking new i5 in place in the very near future, but I've run into a minor stumbling block regarding the new workstation. You may remember that I did some research and as it turns out, the IBM xSeries falls under the Technology Access Program (another one of those well-guarded, top-secret IBM incentive programs), and with the discounts afforded by that program, I can get a screaming dual-3.2 GHz processor machine with 2 GB of RAM and 146 GB of RAIDed 15000 RPM disk for around $3,000. With that sort of price, I'd be a fool not to go with the industrial strength xSeries as opposed to a consumer-class "server" machine from one of the well-known consumer PC suppliers.
Unfortunately, I haven't been entirely successful with this part of the project. I'm close; at this writing I've managed to work through all the issues but one. The last question centers on the correct RAID configuration for my machine. The comparison between RAID-1 (also known as mirroring) and RAID-5 is not as clear-cut as I thought at first, and it gets considerably more complex as the variables increase, such as number of disk drives and the server workload. The definitive IBM publication on the issues clearly and unswervingly states that "it depends" and then brings two new configurations (RAID-1E and RAID-5EE) into the mix, and so I'm looking to see if there is help within the IBM organization.
After a little confusion, my contacts at IBM have gotten me in touch with someone from the labs, but I don't think this is a standard procedure. What I really want is a fairly simple way for prospective buyers to perhaps fill out a form or something and be directed to the appropriate RAID configuration for their workload. But short of that, I can at least share my experience once I've finalized the machine. I don't think there will be a significant difference either way, but I prefer to go into such decisions with as much knowledge as possible.
And rest assured that whatever I learn, you will soon know as well.
Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been working in the field since the late 1970s and has made a career of extending the IBM midrange, starting back in the days of the IBM System/3. Joe has used WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. Joe is also the author of E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. You can reach him at

Joe Pluta is the founder and chief architect of Pluta Brothers Design, Inc. He has been extending the IBM midrange since the days of the IBM System/3. Joe uses WebSphere extensively, especially as the base for PSC/400, the only product that can move your legacy systems to the Web using simple green-screen commands. He has written several books, including Developing Web 2.0 Applications with EGL for IBM i, E-Deployment: The Fastest Path to the Web, Eclipse: Step by Step, and WDSC: Step by Step. Joe performs onsite mentoring and speaks at user groups around the country. You can reach him at
MC Press books written by Joe Pluta available now on the MC Press Bookstore.
 |
Developing Web 2.0 Applications with EGL for IBM i Joe Pluta introduces you to EGL Rich UI and IBM’s Rational Developer for the IBM i platform. List Price $39.95 Now On Sale
|
|
 |
WDSC: Step by Step Discover incredibly powerful WDSC with this easy-to-understand yet thorough introduction. Now On Sale
|
|
 |
Eclipse: Step by Step Quickly get up to speed and productivity using Eclipse. Now On Sale
|

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online