








If you’ve ever done any work in database design, you’re familiar with the concept of using “codes” to represent various forms of data. Codes take up less space on disk, a fact especially important to those of us designing systems anytime prior to the last few years. Online and offline storage used to be really expensive, and we had to design fully functional systems while using the least amount of DASD (disk) possible. (This is how the six-digit date came about, but that is a topic best reserved for another story.)
Quacks in the Armor
Using codes in your database has its problems, however. The most obvious problem is that you create a situation that requires extra I/O processing whenever you need to translate codes into text. It’s a trade-off between how much storage space you use on disk and working the disk access arms off until they’re nubs.
Another problem with codes is that they aren’t always entirely useful when you want to sequence data for reporting purposes. For example, suppose a transaction file contains charges, payments, and adjustments all stored in a single data file, and a transaction type code differentiates each type of transaction. (For this example, we’re using type codes C for charge, P for payment, and A for adjustment.) And as long as we are making suppositions, let’s say the transaction file happens to be the largest file on the system and contains 10 million records. Now, suppose a client calls up and requests a transaction report that usually prints in adjustment/charge/payment order be changed so that it prints in charge/adjustment/payment order. This seems like a simple enough change, but, upon further review, you realize that this may be a bigger job than you thought. The report prints in the order it does because the codes for adjustments, charges, and payments are A, C, and P, respectively. If the client asks you to report the transactions in payment/charge/adjustment order, you would simply process the transactions in descending order by transaction type code. However, because this isn’t the case, your only options seem to be to create a work file keyed in the desired sequence, to use multiple logical files over each type of record, or to change the program to make multiple passes through the data file. Each option involves a dramatic increase in processing time, a luxury you can’t afford, so how do you accomplish this task?
Ducking for Cover
A more logical approach is to use a table file to create an alternate collating sequence that allows the system to read the transaction file in the desired sequence in a single pass through the data. To do this in the example, you would position code C before code A so the report could print the transactions in charge/adjustment/payment order.
Rubber Ducky, You’re the One!
The Create Table (CRTTBL) command enables you to create a table that both logical files and the Open Query File (OPNQRYF) command can use to alter the normal character sequence. To create a table like the table in Figure 1, key in the following command:
CRTTBL TBL(QGPL/TRANSORT)SRCFILE(*PROMPT)TBLTYPE(*SRTSEQ)
The Table type (TBLTYPE) parameter accepts three codes: *CVT, which creates a conversion table; *SRTSEQ, which creates a sort sequence table; and *UCSSRTSEQ, which creates a Unicode sort sequence table. *CVT changes a character from one hexadecimal value to another; *SRTSEQ simply alters the sequence in which characters are processed. *SRTSEQ and *UCSSRTSEQ use different standards to create sort sequence tables, but we use only *SRTSEQ because *UCSSRTSEQ requires a hexadecimal code point and weight for each character.
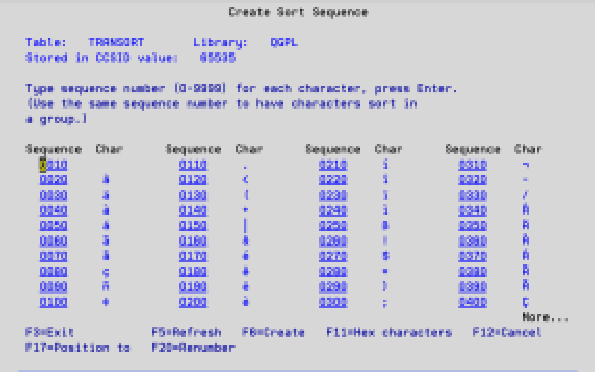
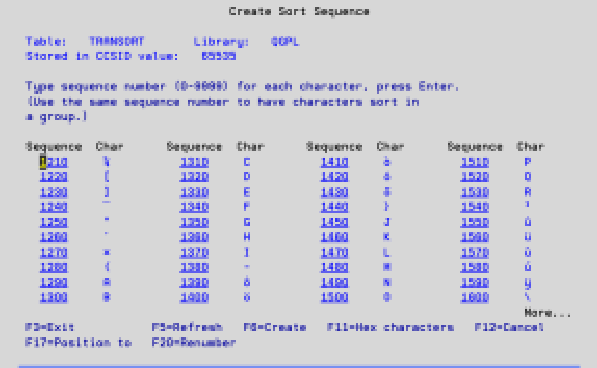
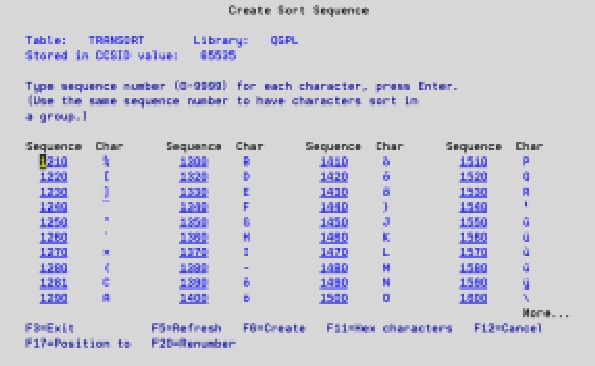
The SRCFILE parameter requires the name of a source file member that contains the hexadecimal conversion characters used to create the table. You can specify a source member name, but we find it easier to use the *PROMPT value for the SRCFILE parameter. *PROMPT prompts a screen similar to Figure 1. The numbered sequence column is the order in which the character in the next column is processed. In our example, you want transaction records with type code C (charges) to appear in the file before transaction records with type code A (adjustments). This being the case, you must press the Page keys until you find C, which is sequence number 1310 (see Figure 2). A is sequence number 1290, so it normally appears before C. However, if you change the sequence number of C to 1281 and press Enter, C now appears before A. (Figure 3 shows the results of making this change.) As soon as you’re happy with your sort sequence, press F6 to create the table.
The instructions on the screen tell you to key in the same sequence number to have characters sort in a group. An alternative sort sequence table might be useful when you have mixed-case characters (possibly a name) in a field and want to sort on that field. If you key in the same sequence number for the lowercase “a” and uppercase “A,” for instance, the two characters sort as if they contain the same value.
Figure 4 shows sample DDS from a logical file that uses our table. The table is named TRANSORT and can be found in library QGPL. The ALTSEQ keyword, at the DDS file level, instructs the file to use an alternative sequence stored in TRANSORT. There are two key fields for this logical file, but you want the table applied only to the TRTYPE key field because TRTYPE contains the transaction type code. The NOALTSEQ keyword tells the system not to apply the table to this field.
OPNQRYF can also use a sort sequence table. The SRTSEQ parameter specifies the name of the table to use.
Everything Is Just Ducky!
If you work with large database files, you will find that the fewer times you have to pass through the file, the more efficiently your system processes. “Tricking” the system to read data in an alternate sequence may save you quite a bit of processing. This is just another example of how knowledge is power!
 |
 |
 |
A ALTSEQ(QGPL/TRANSORT)
A R TRNREC PFILE(TRANS)
A K TRTYPE
A K TRFAM# NOALTSEQ
Figure 4: This logical file DDS uses an alternate sort sequence table.
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online