








HACMP and data replication each serve different needs in the high availability and disaster recovery arenas. Combining the two delivers the best of both worlds.
Many AIX shops protect the availability of their applications by using IBM's High Availability Cluster Multi-Processing (HACMP) to closely link multiple servers connected to shared storage. HACMP monitors the health of the cluster and can automatically recover applications and system resources on a secondary server if the primary server is unavailable. Because the cluster typically operates in a shared-disk environment, as depicted in Figure 1, failover times are very short in this scenario because the failover occurs entirely within the local cluster.
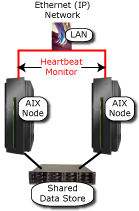
Figure 1: In the HACMP Cluster environment, the shared data store is the weak link.
Looking at Figure 1, there is an obvious vulnerability: the shared data store. This is typically protected by RAID, but that only protects against damage to a disk within an array of disks. If the whole data center is destroyed, such as may happen if a disaster strikes, RAID will not save the shared data store.
What's more, if all of the cluster nodes are located in the same room or building, or even if they are spread across a single office campus, they may all be destroyed in the event of a hurricane, earthquake, or similar disaster. In short, AIX clustering with HACMP does an excellent job of preventing downtime due to individual component maintenance or failures, but it does not protect applications and data from disasters.
Most organizations that use HACMP clusters back up their data to tape each night to safeguard it. Should a disaster destroy the shared data store, and possibly the entire primary data center, data can be recovered from the offsite backup tapes.
There is nothing magical about HACMP clusters in this regard. Tape-based recovery in these circumstances suffers from all of the deficiencies that tape-based backup and recovery approaches exhibit in any environment. The most obvious weakness is speed. Even with modern high-speed tape drives, restoring a full environment could take several hours or even a few days, particularly if the tape needs to be retrieved from offsite.
Another often-discussed vulnerability of tape is the incompleteness of the data on backup tapes. Backup jobs are usually run daily, typically in the middle of the night. If a disaster destroys the data center the next day, none of the data inserts, updates, or deletes entered into the system throughout that day up to the point of failure will be captured on a backup tape.
This problem is compounded when organizations retain the most recent backup tape onsite so they can recover from local data corruptions and accidental deletions, which are much more frequent than disasters. Not having to recall an offsite backup tape greatly speeds the recovery from these types of local data problems, but it means that the most recent backup tape may be destroyed in a disaster that destroys the data center.
Data Replication
Data replication software can eliminate the shortcomings of tape backups. This software monitors data writes--inserts, updates, and deletes--on the production databases and copies those changes to a data store at a remote site. That data store is typically connected to an AIX server that can assume production operations if necessary.
As depicted in Figure 2, a disk-based disaster recovery solution of this type replicates data to a geographically distant location. This can happen synchronously or asynchronously, via either an IP-based connection or a proprietary connection, such as ESCON.

Figure 2: Replication-based disaster protection replicates data to a distant location.
Synchronous replication offers the most complete data protection in that a write request on the production server is not considered to be complete until an equivalent write is applied to the remote disk. As a result, there are never any data writes sitting in a local server cache waiting for replication to the backup.
Synchronous replication can create an obvious problem when fast application response is essential. Data transmission over great distances, including passing through a number of communications devices, such as routers and hubs, is not instantaneous. And when the network is congested, transmission times will be even longer. Consequently, the need to send a write to a remote disk and wait for a confirmation to be sent back might impede application response times unacceptably.
In contrast, asynchronous replication buffers data for replication at the local server. An application's write request is considered to be complete when the data is written locally. Thus, unlike synchronous replication, asynchronous replication does not slow application response, and it can normally cope well with network outages.
Because of the potentially significant response-time impact of synchronous replication, most organizations choose asynchronous replication. This might put some data at risk if a disaster strikes, but with adequate capacity in the network and at the local and remote servers, the replication lag should be minimal.
One important issue to consider when evaluating replication solutions is write-order fidelity. In some cases, if data writes are performed in a different order on the remote server than on the production server, the ability to recover applications accurately may be jeopardized. Write-order fidelity ensures that the data image on the backup data store is always consistent with the data image on the production data store.
Automated Failovers…or Not
Disaster recovery replication solutions can often detect a primary system failure and automatically initiate a failover to the backup location. This is usually left as an administrator-selectable option, and for good reason. The problem is wrongly declared failures.
It is usually quite simple to detect the failure of a local network or a local system component. In this scenario, when the system detects a failure, it typically truly is a failure. Moreover, even if the system incorrectly detects a failure, the consequences of failing over to another node in a local cluster are minimal.
Detecting primary system failures becomes much more complex when the disaster recovery cluster extends beyond the boundaries of the primary site. The backup node must, necessarily, assume responsibility for declaring primary system failures because, if that job were left to the primary system, a primary system failure would result in the failure of the processes involved in detecting system unavailability.
However, when the primary and secondary servers are geographically separated, an outage in the network connection between the primary site and the backup site would, to the backup server, look the same as an outage of the primary node. The secondary mode may, therefore, initiate a failover when the primary system is working perfectly. This can cause an unnecessary disruption to operations.
Thus, despite the fact that automated failover initiation will shorten the failover time by eliminating human reaction times, considerable thought should be given to whether automated or manual failover initiation is the best option in your environment.
Even if you elect to initiate failovers manually, the replication software should still offer facilities to automate the processes involved in those manually initiated failovers as this can significantly shorten failover times, while also dramatically reducing the possibility for human error.
The opportunity to reduce human error should not be discounted. In tense situations, such as when the IT staff is under extreme pressure to bring operations back online as quickly as possible after a disaster, human error is much more likely. If errors occur, they will serve only to worsen an already frantic situation.
The Best of Both Worlds
Remote failover might be measured in minutes, or at most a few hours, but it will not take anywhere near as long as it takes to recover a data center from backup tapes. Nonetheless, even when using automated failover features, a failover to a remote site will not happen as quickly as a failover within an HACMP cluster.
It is possible to get the best of both worlds by combining HACMP local clustering with remote replication and failover capabilities, as shown in Figure 3.

Figure 3: Combining local clustering with remote replication is a better bet than choosing only one or the other.
In this case, when the primary server goes down or must be taken offline for maintenance, a rapid, HACMP-managed local failover can keep operations going. And if a disaster knocks out the entire primary data center or if the shared local data store fails, operations can be quickly switched to the remote data center.
Rolling Disasters
Mention the word "disaster" and most people think of a near-instantaneous catastrophe--fire, flood, earthquake, hurricane, tsunami, terrorist attack, or the like. However, those aren't the only types of disasters that organizations must contemplate.
Another disaster scenario that must be taken into account is generally referred to as a "rolling disaster." In this case, there isn't a single "big bang." Instead, there is a cascading series of "whimpers."
In a rolling disaster, system components begin to fail gradually, with one component failure possibly triggering the next. Depending on which components fail first, replication to a backup data store may continue until the failure cascade reaches a critical point.
Depending on the nature of the failure, the local data copy may become corrupted before the system stops completely. In this case, because replication will likely continue until the final point of failure, data corruptions will be replicated to the backup data store, corrupting it as well.
Because of the potential for rolling disasters, it is important to keep "point-in-time" images of all of your data. These images may be traditional tape backups, or preferably, they can be more-frequent disk-based snapshots.
At best, taking snapshots strains the system, or at worst, it may require quiescing the applications using the data. Thus, for systems that are required 24x7, the taking of data snapshots is practical only if you have a replica data store. Snapshots can then be taken on the replica without impacting the primary system.
The "Other" Recovery Requirement
Subject to the limitations discussed above, nightly tape backups protect most data, but they allow you to recover data to only a single point in time--namely, when the backup tapes were created, which may be up to 24 hours prior or even longer if the most recent backup tapes were destroyed or corrupted.
In a sense, remote replication of data also allows you to recover data to only a single point in time. However, in this case, the point in time is right now. That is, you will have a reliable copy of the primary data store only as it was at the point of failure.
But what if the data was already corrupted when the failure occurred, such as might happen during a rolling disaster? Or what if there was no failure at all, but the primary data store has, nonetheless, become corrupted somehow, such as because of a computer virus or because a file was accidentally deleted?
Neither backup tapes nor remote replication offer an ideal solution. In fact, replication alone may offer no solution at all as the data corruption will likely have been replicated when it happened. And recovering from tape is typically slow, and, worse, you are forced to recover the data to its state when the tape was created. Yet the data may have been updated several times between the creation of the backup tape and the time the data corruption occurred. Those updates will be lost when you recover from the nightly backup tape.
Continuous Data Protect (CDP) offers a way to fulfill this data recovery requirement. Traditional replication technologies capture changes made to a production data store and transmit copies of those changes to a second system, where the changes are immediately applied to a replica of the primary data store. Traditionally, the replication software discards the updates after they are successfully applied to the replica database.
In contrast, CDP, which is available both as a feature of some replication software and as standalone software, stores copies of the individual changes on storage attached to a secondary server, without necessarily applying the updates to a database replica.
Should an individual data item become corrupted and the time of the corruption is known, the CDP software typically provides for "push-button" recovery of that individual data item to its state immediately before the corruption occurred.
CDP comes in two generic flavors. True-CDP continuously transmits data changes in near real-time to a secondary server. As a result, data can be recovered to its state at any point in time. Near-CDP, on the other hand, transmits changes to the backup system only periodically--typically, when a file is saved or closed. Consequently, recovery can be made to only discrete recovery points, rather than to any point in time. Depending on the near-CDP algorithms and the nature of the applications updating the data, these recovery points could be spaced hours apart. This may be inadequate for companies that have high transaction volumes or that operate under strict data-protection regulations or internal standards.
What to Look for in Replication Software
As discussed above, if you're running an AIX environment and depending on HACMP alone for high availability, your data is vulnerable even if you faithfully create nightly tape-based backups. What's more, the time required to recover from tape may be too long to meet business requirements.
Replication offers a way to resolve these problems, but what should you look for in a data replication solution? The following is a checklist of features you should consider:
- The software should be designed specifically for the AIX operating system so it will be as efficient as possible, thereby minimizing the load on the system.
- The ability to detect primary system outages and automatically initiate a failover can reduce failover times, but its use should be optional because there are circumstances in which its use is ill-advised.
- Even though you may choose to manually initiate failovers, the software should automate as much of the failover process as possible in order to shorten failover times and minimize the possibility of human error.
- CDP fills a critical gap in many organizations' data protection strategies--namely, it allows recovery of individual data items to a particular point in time to reverse a data corruption or recover an accidentally deleted file.
- A snapshot facility allows you to create disk-based images of your data. This enables faster recoveries than tape-based solutions. Snapshots also allow you to quickly create realistic "sandboxes" to facilitate software testing under real-world conditions.
- If you use HACMP as your primary high availability solution, the replication software must integrate well with HACMP.

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online