








Explore current methods of interconnecting SQL Server to the IBM i in batch or real time.
Astronomers tell us that many galaxies are colliding, which can cause quite an upheaval. "Collision" is a good word to describe how some shops feel about intermingling the System i (AS/400, iSeries…) with other technologies. SQL Server and DB2 are both large product families, and there are many integration options to consider. IT personnel want to know: Do we invest in learning the tools that IBM and Microsoft supply, or should we buy a third-party package to ease the integration pains?
This article is intended to reveal the many ways IT can make the two platforms coexist using nothing more than the basic developer tools that come with each platform. It will also detail how to connect the two systems using SQL Server Integration Services (SSIS) and address how to create an ad hoc connection to a DB2 remote data source from SQL Server.
A Recap from the Past
(Author's Note: Detailed information on most of these concepts can be found in prior MC Press articles. See the reference section at the end for more information.)
In the beginning, the "linked server" facility was made available in SQL Server 7.0. This allows SQL Server to read and write directly to DB2 (and other database) tables and views using nothing more than an ODBC driver or OLE DB provider. This feature made the SQL developer's job much easier by allowing JOINs or INSERTs to occur on tables in heterogeneous database servers. Integration with i became a snap because data could be transferred so easily between the two databases, as shown in this conceptual SQL Server T-SQL statement:
Insert Into DB2Table
Select *
From SQLServerTable
Where Not Exists
(Select *
From DB2Table
Where DB2Table.UniqueKey=SQLServerTable.UniqueKey)
Starting with SQL Server 2005, Microsoft enhanced the Linked Server facility by introducing the EXEC AT statement. EXEC AT allows "passthrough" queries such that SQL Server can pass database servers such as DB2 and Oracle SQL statements in their own proprietary dialect of SQL. This means that DB2's Data Definition Language (DDL) statements and stored procedures (CALL statements), for example, can be executed from within SQL Server. The other major enhancement provided by EXEC AT is the ability to submit parameterized queries to the remote database. Basically, Transact-SQL (T-SQL) developers now have a fine-grained control over how SQL Server will interact and exchange data with the i in a way that was only available to traditional developers using languages such as Java, .NET, VBA, etc.
SQL Server and i can play very well together as it is possible to execute cross-platform transactions (aka "distributed transactions") when using linked servers. A distributed transaction between SQL Server and i ensures that updates within a transaction must complete successfully on both platforms before the data is committed.
In case all of this isn't enough, in SQL Server 2005 and beyond, Microsoft has given developers the option to extend the database functionality by writing trigger, scalar function, table function, user-defined type, aggregate, and stored procedure code in a .NET language. This is similar to how DB2 for i developers can create "external" stored procedures or functions in a high-level language (HLL) such as C, Java, RPG, or COBOL. With this in mind, it is possible to make available to T-SQL just about anything the .NET environment can gather. For instance, a .NET "stored procedure" can simultaneously access a DB2 query result set and combine it with data from a Web service call. This makes coding easy (invoking a stored procedure is trivial) and also makes SQL Server one cool "data access anywhere" product.
If you only need to pull data into SQL Server from DB2 (and not the other way around), then SQL Server 2008 offers a great new T-SQL statement called Merge. Merge can read data from DB2 (and other database servers) and apply appropriate inserts, updates, and deletes against a SQL Server view or table to make sure the data between the two is consistent. Merge even gives developers the ability to apply transformations to the DB2 data before updating the local SQL Server data!
Out of the initial options listed thus far, I would recommend sticking with linked servers as the method of choice due to its ease of configuration and coding if you're working with small-to-intermediate-sized data transfers.
Reporting
SQL Server also offers a fine SQL-based reporting module called SQL Server Reporting Services (SSRS). SSRS can report from a variety of data sources out of the box, including DB2 for i.
A 180-Degree Recap from the i Perspective
Thus far, we've discussed options for SQL Server to initiate a data transfer with the IBM i whether doing a push or a pull. But what if we want the opposite? What if an i program should control how and when the data is exchanged?
IBM i can control SQL Server operations. One of the easiest ways to do this is by using Java and the SQL Server Java Database Connectivity (JDBC) driver. For instance, a Java program running on the i can connect to SQL Server and modify data, execute a batch script, or run a stored procedure.
Even though many i programmers are still leery about entering the Java world, the good news is that RPG and COBOL programmers can be shielded from the complexities of Java by wrapping the Java program calls with SQL. This means that a Java call to get data from a SQL Server table can be reduced, in principle, to the following simple SQL Select:
Select * From MyJavaProgram
The article "Query Remote Database Tables from the iSeries Using SQL and Java" details how to write a Java User-Defined Table Function (UDTF) to allow the i access to data from SQL Server or any other database with a JDBC driver.
Along the same lines, the article "Execute Remote Stored Procedures from the iSeries" discusses how a Java program can be used to execute a stored procedure in a remote database. Further, the complexities of the Java call can also be masked by using an SQL wrapper to make the final usage almost as simple as this:
Call MySQLServerProcedure
Indeed, a high-level language i program can use embedded SQL or even something like RPG's Java Native Interface (JNI) to work with Java objects that control interaction with SQL Server.
What Else Can We Do?
The good news is SQL Server has a few more tools to offer: Integration Services, OpenRowset, and replication. Each option has its own strengths and weaknesses.
SSIS
One important tool SQL Server 2005 and beyond offers is SQL Server Integration Services (abbreviated SSIS and formerly known as Data Transformation Services (DTS) in SQL Server 7.0 and 2000). SSIS has many capabilities, including the ability to transfer data between databases, Excel files, flat file data sources, and FTP data sources. It can also perform non-transfer tasks such as doing database backups, sending an email, executing a specific SQL statement, and more.
SSIS is a huge topic, but for now, I'll do a quick demonstration of how to push data from SQL Server to DB2 using SSIS on SQL Server 2008 using data from the Adventure Works 2008 sample database. SQL Server 2005 users can do their best to follow along; unfortunately, space doesn't permit covering both. Also, I'll be using the System i Access (aka Client Access, iSeries Access) data providers, including the ODBC driver and the IBMDASQL OLEDB provider. For the record, I'm using System i Access V6R1 with the latest service pack.
Here are the steps to get started with an SSIS data flow project:
- Start Business Intelligence Development Studio 2008 (BIDS). (Note: BIDS is just a specialized version of Visual Studio that comes with project type templates specific for SQL Server. BIDS is installed as part of the SQL Server client components and can be installed on a developer workstation without the database engine itself. If you're unfamiliar with BIDS, get a quick overview here: Introducing Business Intelligence Development Studio. You will need to understand references to the Solution Explorer, etc. to continue.)
- Choose New Project.
- Under project types, select Business Intelligence Projects. If you don't have this option available, attempt to install (or reinstall) BIDS from the SQL Server installation media.
- Choose Integration Services Project, assign the project a name and location, and click OK. I called my test project DB2_SQL.
You should now have an empty designer screen that looks like Figure 1 below:
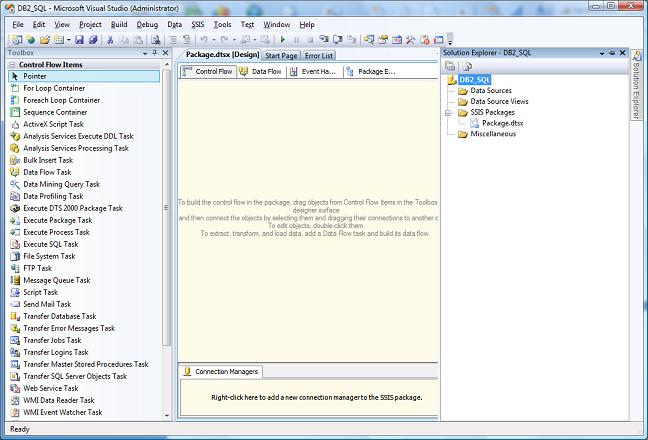
Figure 1: You'll start with an empty SSIS designer screen. (Click images to enlarge.)
The left side of the default BIDS layout contains a toolbox with "Control Flow Items," which will let you do many things, including add logic to your package, send an email, run an ActiveX script, access the file system, and perform a "Data Flow." Data Flow is what we're going to focus on as it is used to push or pull data between data sources.
Often, a BIDS package intended to transfer data is created by defining source and remote data sources (these are connections to the databases, files, etc.), followed by dragging various tools from the toolbox onto the designer surface shown in Figure 1, followed by setting various tool properties, and so on.
This is quite a bit for a beginner to learn to do, so we'll take the easy way out and use the Data Transfer wizard to get things set up for us. This wizard will create our source (SQL Server) and destination (DB2) data sources and create a data flow task that will instruct the SSIS package on what data to move. Once you get comfortable with what the wizard builds, you can start designing your own packages from scratch.
Usually I don't like "Mickey Mouse" examples, so I wanted to pick a data transfer problem with a bit of a twist. Often, I use linked servers to move data between systems. However, linked servers don't support large object (LOB) column transfers, so I decided to include a large object column in this example. In particular, we'll use SSIS to transfer the Production.ProductPhoto table, which contains Binary LOB (BLOB) columns ThumbNailPhoto and LargePhoto.
Here is the SQL Server table definition:
CREATE TABLE Production.ProductPhoto(
ProductPhotoID int IDENTITY(1,1) NOT NULL,
ThumbNailPhoto varbinary(max) NULL,
ThumbnailPhotoFileName nvarchar(50) NULL,
LargePhoto varbinary(max) NULL,
LargePhotoFileName nvarchar(50) NULL,
ModifiedDate datetime NOT NULL,
CONSTRAINT PK_ProductPhoto_ProductPhotoID
PRIMARY KEY CLUSTERED (ProductPhotoID ASC))
Note that varbinary(max) is SQL Server's equivalent of the DB2 BLOB data type.
The DB2 table definition looks like this:
CREATE TABLE MyLib.ProductPhoto (
ProductPhotoID INTEGER NOT NULL PRIMARY KEY,
ThumbNailPhoto BLOB(64K),
ThumbnailPhotoFileName VARCHAR(50),
LargePhoto BLOB(512K),
LargePhotoFileName VARCHAR(50),
ModifiedDate TIMESTAMP)
For simplicity, the column names will be exactly the same and the data types compatible, although it is certainly possible to do column mappings and data type transformations. The DB2 table does not have to exist at the time we create the SSIS data flow.
To get going with the data transfer:
- Start the wizard by choosing "SSIS Import and Export Wizard" from the Project menu.
- Skip the Welcome screen if it shows up.
- On the "Choose a Data Source" step, pick the ".Net Framework Provider for SQL Server." (You probably have more than one potential SQL Server data provider in your list of possible providers.)
- Once the .NET provider is selected, a Properties window will appear. Locate the "data source" property and fill in your SQL Server's host name. Locate the "Initial Catalog" property and put in your SQL Server database name (I'm using the AdventureWorks2008 database). Finally, you'll need to fill in your SQL Server user name and password or simply set "Integrated Security" to true if you're using Windows authentication. Now SSIS knows how to get into the source database. Click Next.
- On the "Choose a Destination" step, choose the "IBM DB2 for i5/OS IBMDASQL OLE DB Provider." (Again, I have at least six ways to connect to the IBM i, but I chose IBMDASQL for reasons I'll explain later.)
- Once IBMDASQL is selected, click the Properties button. When the DataLink window opens, locate the following properties and enter the required information to connect to the i: Data Source (your i host name), User Name and Password (i user name and password; you may need to uncheck the Blank Password box and also click Allow Saving Password).
Click the All tab at the top of the window for more properties. Locate the Default Collection property and enter the name of an i data library that is safe to test with. This Default Collection property tells DB2 where to look for all unqualified table and view names.
SSIS now knows how to connect to the i and what library to place the data in.
Click OK. Back at the wizard, click Next. - On the "Specify Table Copy or Query" step, choose "Copy Data from one or more Tables or Views." This will allow us to copy a SQL Server table directly to DB2. The other option here is to create a SQL Server T-SQL query that we could copy into a table within DB2. Click Next.
- On the "Select Source Tables and Views" step, a list of available tables and views from the source database will appear. Locate the "Production"."ProductPhoto" table and check the box next to it. Click the "Edit Mappings" button. You should get a screen like Figure 2 shown here:

Figure 2: This "Column Mappings" window displays how SQL Server intends to map data between the source table and the destination table.
As you can see from the grid, SQL Server doesn't know very much about DB2 data types. For example, the photo columns are being mapped to a VARCHAR() FOR BIT DATA column instead of a BLOB. Also, it's mapping SQL Server NVARCHAR to VARGRAPHIC with a CCSID of 13488, which is OK, but better would be to VARGRAPHIC with CCSID 1208 (UTF16) or to NVARCHAR on a V6R1 (6.1) system. Fortunately, we have the ability to override these types. In this case, we're just going to map the SQL Server NVARCHAR to a VARCHAR with the i's default CCSID.
- Click the Edit SQL button. Here, you will see how SQL Server would issue a CREATE TABLE statement to build the table on DB2! It goes without saying this statement will fail, so it will need to be replaced with a valid CREATE TABLE statement that will run on DB2. Paste in the DB2 CREATE TABLE statement shown above (replacing MYLIB with your test library name) and click OK.
- Back at the Column Mappings window, you'll notice a warning that states the data type values shown on the screen may not reflect the actual metadata in the DB2 table. Since we did our own CREATE TABLE statement, this warning is OK. Click the "Drop and re-create destination table" button. When the SSIS package runs, this will cause SSIS to drop the table (if it exists) and re-create it. Click OK to return to the wizard and then click Next.
- On the "Convert Types without Conversion Checking" step, click Next.
- On the "Complete the Wizard" step, take note of the information given (including the package that will be created) and click Finish.
- The final wizard screen will generate an SSIS package. Click Close to return to BIDS.
You will notice that a package called Package1.dtsx is now open within BIDS and populated with controls on the designer screen, as shown in Figure 3. (A file with a DTSX extension represents a single SSIS package within an SSIS project.)

Figure 3: The "Control Flow" tab now has three tasks defined: SQL Task (Drop Table), Preparation SQL (Create Table), and Data Flow Task.
Notice that at the top of the middle window there are four tabs: Control Flow, Data Flow, Event Handlers, and Package Explorer. The Control Flow tab contains the major tasks to be executed in the package.
These are the three tasks the wizard created for us:
- An SQL Task to drop the existing DB2 table if it exists. (In general, the SQL Task is used to run an SQL statement against a data source. When creating a package manually, you'd drag an SQL Task from the toolbox and drop it on the Control Flow designer panel.)
- An SQL Task to create the table in DB2. (These tasks appear because we chose the "Drop and Re-create Table" option.)
- A Data Flow task that manages how the data moves between the source and destination tables. More information about the Data Flow can be found in the Data Flow tab.
Let's see what the wizard did for us. Click on the "Drop table(s) SQL Task 1" graphic on the Control Flow designer and then press F4 to bring up the task's properties. Examine the SQLStatementSource property contents, which should look like this:
drop table ProductPhoto
GO
This DROP TABLE statement looks like it was intended for SQL Server because it has the GO command appended! Remove the GO from the statement. Since this SQL Task is defined to run against DB2, it should have a DROP TABLE statement that uses DB2 syntax. Locate the Name property and enter the following: Drop DB2 Table. This name should now show up in the box on the designer.
Next, click on the "Preparation SQL Task 1" box and Press F4 to show the properties window. This SQL Task is intended to issue the CREATE TABLE statement on DB2. Locate the Name property and enter the following: Create DB2 Table. Locate the SQLStatementSource property, which should contain the DB2 CREATE TABLE statement. Remove the GO from the end of the statement.
Click on the "Data Flow Task 1" box, press F4, and enter the following in the Name property: Push Data to DB2.
Here's where the fun begins. Press F5 to run this package. When finished, the Control Flow tab will probably look like Figure 4:

Figure 4: This is how the Control Flow tab looks once the package is run.
Each task will take on the color red (if the task fails) or green (if the task succeeds). The "Drop DB2 Table" task is red because it could not drop a nonexistent table. This failure is OK. The green "Create DB2 Table" indicates the table was created. The red "Push Data to DB2" task indicates that the data was not moved to DB2! For the record, even though the SSIS package has run and completed, you will still need to "stop" the project by clicking the Stop button on the toolbar or by clicking the message at the bottom of the window that allows you to switch back to design mode.
There is now also a Progress tab on the designer window that gives us detailed information on what happened while the package was running. Click on the Progress tab now and review the messages under each task. Upon reviewing the messages, you'll see that the "Drop DB2 Table" step failed with an SQL0204 (object not found) because the table didn't exist yet. This is OK. The "Push Data to DB2" task failed with this message:
[Destination - ProductPhoto [34]] Error: There was an error with input column "ModifiedDate" (63) on input "Destination Input" (47). The column status returned was: "The value could not be converted because of a potential loss of data.".
We can see this error involves the ModifiedDate column, which is a SQL Server DateTime data type being pushed into a DB2 TimeStamp. Browsing through the SQL Server table's data, I found that some of the DateTime values contain fractional seconds. Even though the DB2 TimeStamp can actually hold a greater range of values with a greater precision (down to the microsecond), some logic within the deep, dark recesses of the OLE DB provider is causing a stink because it thinks it may be losing some data with these fractional seconds!
The fix for this problem is easy enough; we can just truncate the fractional seconds from off the DateTime column. We can do this by changing the data flow portion of the SSIS package. Click the Stop button to halt debugging (if you haven't done it already) and click the package designer's Data Flow tab (at the top).
Click on the "Source – ProductPhoto" icon and press F4. This icon represents the package's source table (SQL Server ProductPhoto table). Find the AccessMode property and set it to SQL Command. Choosing SQL Command will allow us to enter any valid T-SQL query statement (including a stored procedure call) in the SQLCommand property. Find the SQLCommand property and paste in the following text:
SELECT ProductPhotoID,ThumbNailPhoto,ThumbnailPhotoFileName,LargePhoto,LargePhotoFileName,Cast(Convert(VarChar(20),ModifiedDate,120) As DateTime) As ModifiedDate FROM Production.ProductPhoto
By telling SSIS we want an SQLCommand instead of directly getting a table or view, we can customize our ModifiedDate column by truncating the fractional seconds and converting it back to a DateTime data type as follows:
Cast(Convert(VarChar(20),ModifiedDate,120) As DateTime) As ModifiedDate
Issuing a query statement against the source database is one of the easiest ways to do column transformations to make sure the source data will be compatible with the destination's data requirements. A SQL statement can do conditional column expressions, remove unwanted NULLs, reformat numeric dates to actual dates, etc.
Now that we've changed the source statement to remove this problem, press F5 again to run the package. Hopefully, when it finishes, all of your boxes on the Control Flow tab will be green and you'll have a copy of the Adventure Works ProductPhoto table on your i!
This example turned out to be a good tutorial because pesky things like this "fractional second" problem can come up in the transformations.
Which Data Provider Should I Use with SSIS?
IBM offers five data providers with Client Access: the ODBC driver; the IBMDA400, IBMDASQL, and IBMDARLA (record-level access) OLE DB providers; and the .NET DB2 Managed Provider.
My first instinct was to try the .NET Managed provider for this project. However, after setting all the properties in the wizard, I ran into this brick wall:
[Destination - ProductPhoto [34]] Error: An exception has occurred during data insertion, the message returned from the provider is: Specified method is not supported.
While it's not much information to go on, I could only conclude from this that the BLOB transfer is not supported with this provider.
I normally like and recommend the ODBC driver because overall I've had the most success with it (compared to the OLE DB providers) in the SQL Server linked server environment as well as in the many VBA projects I've done over the years. Especially when it comes to parameterized statements and system naming convention issues, the ODBC driver has had the fewest problems for me. However, in this SSIS test, the ODBC driver was not cooperating and I couldn't get it to work for this example.
As for the OLE DB providers, I would not use IBMDARLA because it is intended for record access instead of record sets. IBMDA400 is a multi-purpose provider that can access data queues, i OS commands, and SQL functionality. IBMDASQL is optimized for SQL alone, so I stick with it out of these three. I also noticed that the IBMDASQL provider does not include the double-quote qualifiers that are often put on table and column names by default with the other providers.
In this test, the IBMDASQL provider worked the best, but for a different scenario, one of the other providers may work better. If nothing else, IBMDASQL is a good provider to start with.
A Few SSIS Pointers
Here are a few things to think about when using SSIS.
- If you mess up with the wizard, sometimes it's easier to trash the project and start over!
- A single SSIS package can have multiple data flows.
- Variables and conditional logic are allowed within packages.
- SSIS allows event-handling, which can allow, for instance, rows that generate errors to be ignored. In contrast, multi-platform data transfers with linked servers will cause an entire SQL statement to fail if bad data is encountered during, say, an INSERT.
- SSIS can operate without the DB2 journaling requirements that exist when doing multi-platform data transfers with linked servers.
- In a data transfer, you don't always have to drop and re-create the destination table. Instead, you could change the SQL task to DELETE all the rows, clear it by calling a stored procedure intended for this function, or simply issue the Clear Physical File (CLRPFM) command via the SQL interface as follows:
CALL QSYS.QCMDEXC('CLRPFM MYLIB/MYTABLE', 0000000020.00000)
Although SSIS has a learning curve (mostly related to data type compatibility and syntactical differences in SQL dialect between DB2 and SQL Server), it is a useful tool and worthwhile to learn, especially for larger data-transfer projects.
Using OpenRowset and OpenDataSource for Ad Hoc Remote Queries
OpenRowset is very similar to OpenQuery except it allows a T-SQL developer to dynamically connect to a remote data source and execute a query without having to define a linked server first. The benefit here is that a linked server doesn't have to be predefined. All the remote data source connection string properties—such as user name, password, System i library list, commitment control level, etc. —can be established on the fly with OpenRowset. This is useful for environments that may connect to multiple i servers from one or more SQL Servers.
The following examples show sample SELECT and INSERT distributed queries made from SQL Server to DB2 using the IBM ODBC driver and IBMDASQL OLE DB provider.
Using the ODBC Driver
SELECT a.*
FROM OPENROWSET('MSDASQL',
'Driver={iSeries Access ODBC Driver};SYSTEM=My_iSeries_Host;nam=1;cmt=0;DBQ=,CORPDATA;UserID=MYUSER;PWD=MyPass',
'SELECT *
FROM Department
ORDER BY DeptName') AS a;
--
-- Reminder:
-- This INSERT statement requires journaling to be active
-- on the DEPARTMENT table within DB2 to avoid an error:
-- SQL7008 - DEPARTMENT in CORPDATA not valid for operation
--
INSERT INTO OPENROWSET('MSDASQL',
'Driver={iSeries Access ODBC Driver};SYSTEM=My_iSeries_Host;nam=1;cmt=0;DBQ=,CORPDATA;UserID=MYUSER;PWD=MyPass',
'SELECT *
FROM Department
ORDER BY DeptName')
Values('X01','My Dept',NULL,'A00',NULL);
Using the IBMDA400/IBMDASQL OLE DB Provider
Select *
From OpenRowSet('IBMDASQL',
'Data Source=My_iSeries_Host;Initial Catalog=MYRDBNAME;Default Collection=CORPDATA;Password=MyPass;User;Force Translate=65535;Convert Date Time To Char=FALSE;Application;Block Size=1024;Transport Product=Client Access;',
'SELECT *
FROM Department
ORDER BY DeptName') A
INSERT INTO OpenRowSet('IBMDASQL',
'Data Source=My_iSeries_Host;Initial Catalog=MYRDBNAME;Default Collection=CORPDATA;Password=MyPass;User;Force Translate=65535;Convert Date Time To Char=FALSE;Application;Block Size=1024;Transport Product=Client Access;',
'SELECT *
FROM Department
ORDER BY DeptName')
Values('X03','My Dept-IBMDASQL',NULL,'A00',NULL)
Each of these examples simply illustrates the technique of making a dynamic connection. Of course, the connection string keyword requirements will vary by provider and environment.
If you get this error…
Cannot fetch a row from OLE DB provider "IBMDASQL" for linked server "(null)".
…you may need to use the following script to get the IBM data providers to work (substitute IBMDA400 if you're working with that provider):
USE [master]
GO
EXEC master.dbo.sp_MSset_oledb_prop N'IBMDASQL', N'AllowInProcess', 1
GO
EXEC master.dbo.sp_MSset_oledb_prop N'IBMDASQL', N'DynamicParameters', 1
GO
Thanks to the MSDN blog for this tip!
A related function that requires the use of the four-part naming convention within T-SQL is OpenDataSource:
Select *
From OpenDataSource('IBMDASQL',
'Data Source=My_iSeries_Host;Initial Catalog=MYRDBNAME;Default Collection=CORPDATA;Password=MyPass;User;Force Translate=65535;Convert Date Time To Char=FALSE;Application;Block Size=1024;Transport Product=Client Access;').MYRDBNAME.CORPDATA.DEPARTMENT
These are the components of a four-part name within T-SQL (they should all be capitalized when connecting to DB2 for i unless you're using double-quote delimited names):
- Linked server name
- Catalog name (this is DB2's relational database name)
- Schema name (DB2 library name)
- Object name (DB2 Table or View)
As you can see, OpenDataSource allows a connection string to be substituted in place of a linked server name. As with OpenRowset, make sure to call the sp_MSset_oledb_prop stored procedure for the provider you are using, as shown above.
The drawback of OpenRowset/OpenDataSource is that using it for the benefits described above most often requires a developer to use it within a dynamically created SQL script. Since T-SQL doesn't allow the connection string to be placed in a variable, the connection string has to be hard-coded or put in a string variable that is executed dynamically using EXEC() or sp_ExecuteSQL.
However, for one-time problems or even running scripts on multiple SQL Servers, an easily distributed script that uses OpenRowset or OpenDataSource may be preferable to configuring linked servers.
Finally, to use OpenRowset and OpenDataSource the local server must be configured to allow ad-hoc data access. If this option is not already enabled, simply enable it within SQL Server Management Studio or by running the following T-SQL script:
EXEC sp_configure 'show advanced options'
GO
RECONFIGURE
GO
EXEC sp_configure 'Ad Hoc Distributed Queries', 1
GO
Replication
Yet another available option that can be used to exchange data is a SQL Server feature called "replication," which I'll briefly describe. When using replication, you define one or more "publications," which can be tables, views, etc. that you wish to replicate to another system.
After the publications are defined, one or more subscriptions can be defined to consume the publications. If a subscription is defined for a non-SQL Server database (in this case, DB2), the subscription has to be defined as a "push" subscription; that is, SQL Server has to push the data to the subscriber (the DB2 subscriber can't pull the data). Once the subscriptions are defined, SQL Server takes care of propagating changes from itself to the subscriber. This process can be run on demand or scheduled.
I haven't used replication to DB2 in a production environment. I last played with it quite a while back on SQL Server 2000. From what I remember, the biggest issue with the process is that SQL Server has to append a GUID column to both the source and destination tables in order to keep them synchronized. This additional column has the ability to create data type compatibility and re-compile headaches for legacy RPG applications.
For SQL Server 2005/2008, it looks like the replication features have been diminished. Unless I'm missing something, it looks like non-SQL Server subscribers are now limited to using only the Microsoft OLE DB providers for DB2 and Oracle.
For DB2, Microsoft's OLE DB provider is a multi-function provider for all varieties of DB2 and, specifically for i, uses the DRDA interface. Also, it appears that for the SQL Server standard edition, BizTalk Host Integration Server may be required as well, whereas the SQL Server Enterprise edition doesn't have this requirement.
The Choice Is Yours
You have an overwhelming number of ways to connect SQL Server to i, ranging from simple (such as linked servers) to complex (using .NET or Java integration) and anywhere in between (SSIS). Taking time to learn a few of the methods presented in this collection of articles will help bring order to your IT galaxy.
References
"TechTip: MERGE DB2 Data to SQL Server 2008"
"TechTip: SQL Server 2005 Linked Servers and Synonyms"
"DB2 Integration with SQL Server 2005, Part 2: CLR Integration"
"DB2 Integration with SQL Server 2005, Part I: Linked Server Enhancements"
"Execute Remote Stored Procedures from the iSeries"
"Query Remote Database Tables from the iSeries Using SQL and Java"
"Patch Those Leaky Interfaces"
"Rev Up "i" Reporting with SQL Server 2008 Reporting Services"
"Running Distributed Queries with SQL/400 and SQL Server 7.0" in the September/October 2000 issue of AS/400 Network Expert
Replication: IBM DB2 Subscribers
Heterogeneous Database Replication
Replication: Create a Subscription for a Non-SQL Server Subscriber
 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online