








As enterprise applications expand in database requirements and complexity, the need to access multiple databases becomes paramount, requiring multiple applications to co-exist across different platforms.
In POWER environments running legacy IBM i systems, a two-phased approach is required to enable the integration of multiple databases across different platforms.
1. First of all, in order to easily extract data from DB2 for IBM i, you will achieve a lot more by moving to DB2 SQL. You need to convert the database schema from DDS to DB2 SQL (DDL) natively with absolute minimum impact to the rest of the applications running on the system. A fundamental requirement here is that you focus on placing the access and extraction processes in the hands of your SQL-literate users to remove dependencies (constraints) and provide users with unconstrained access to their business information.
2. Then, using native SQL tools and interfaces on the IBM i, it is possible to access specific files on DB2 and non-DB2 remote databases without the need for additional hardware appliances or proprietary software on the remote database.
Get Data from IBM i Out
The first step is to convert the database schema from DDS to DDL, unlocking a host of additional functionality in the SQE interface. This process of conversion can be achieved by extracting structural metadata directly from the compiled objects. Structural metadata is the information contained within a file that describes the structure of the file, not its contents. It's possible to automatically import the underlying structural metadata of all the files in the original schema into the database without relying on source code. This import function extracts the actual information about the structure of the schema directly from the compiled objects and guarantees that the correct production version of the schema is imported without having to locate the correct source code. Once this process is complete, a full definition of the existing DDS schema and its structure is available within a cloned copy of the database. At this time, the cloned database has no data, just information about its structure.
This process can be achieved with or without the need for surrogate logical files. Surrogate logical files masquerade the change to the underlying database, allowing legacy systems to access the new database files without the need for recompilation. Surrogates are beneficial when new applications are being implemented, and legacy applications remain unchanged. Should you, however, aim to leverage the competitive advantage and value of your heritage applications, approximately 80 percent of the lines of code (all lines of code implementing validations and enforcing data relationships) currently in your legacy applications will eventually end up in the database engine. By eliminating surrogate local files, you end up with a far more efficient approach to enabling long-term modernization.
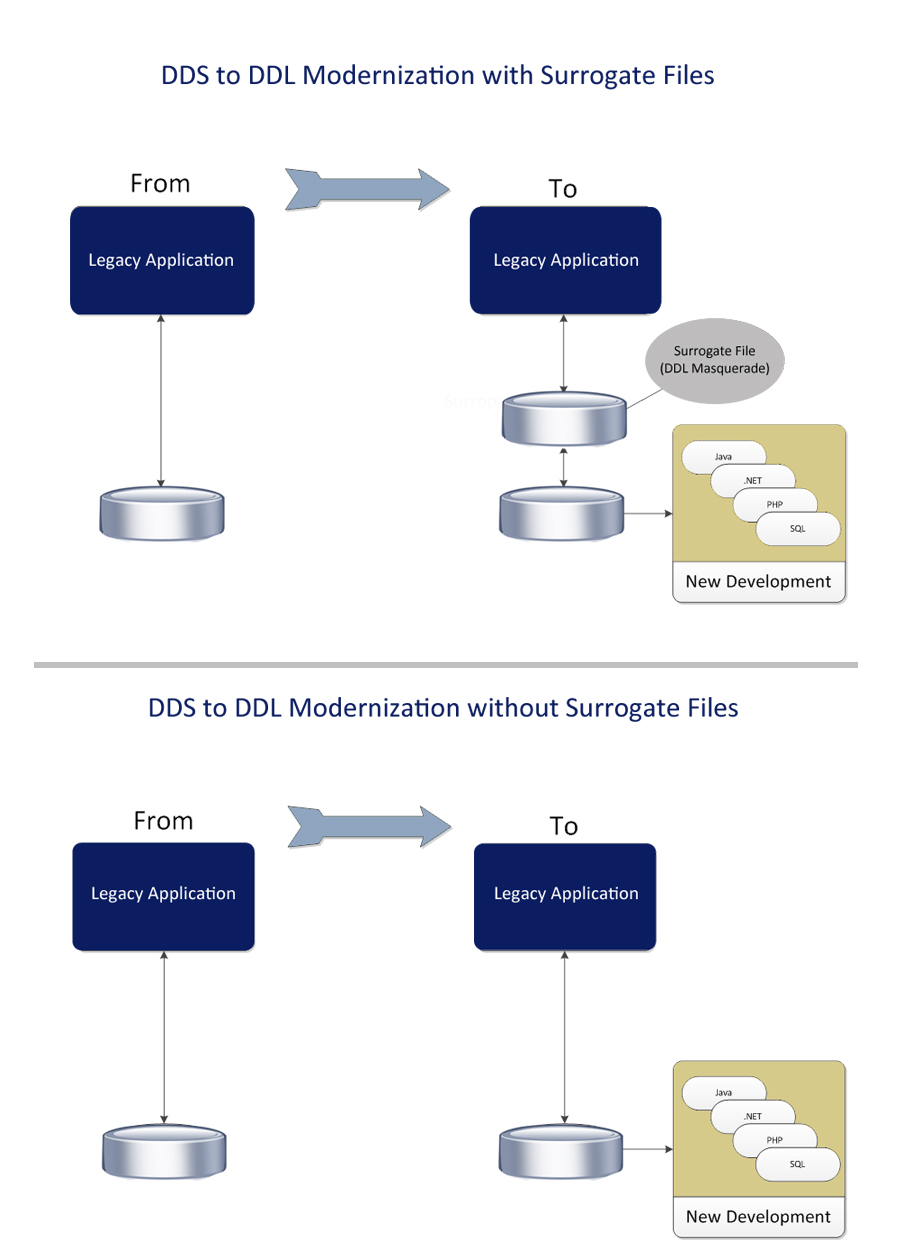
Figure 1: Compare the DDS-to-DDS modernization with and without surrogate files.
The next theoretical step is to register a new schema using the original schema's structural metadata and generate associated DDL statements and database objects from this. This process can be done without changing, manipulating, or massaging the original structural data. The aim of this exercise is to build DDL from the cloned DDS structural metadata without changing level IDs in any way (which is a significant requirement when migrating and upgrading DDS to DDL in phase 1, which facilitates an easy, non-disruptive, low-risk process that is entirely transparent to legacy applications).
The new schema is built using the cloned copy of the structural metadata as its source. This newly registered schema will be the schema into which DDL structures are going to be built. The empty schema is based on the original structure, which matches the original DDS schema exactly, except the DDS files are now native DDL files.
To ensure that the rebuild has been successful, "level ID cross-checking" needs to occur. This can be accomplished by pulling the structural metadata from both the original schema and the new schema, as well as the structural metadata in the cloned database. The cross-check ensures that the structural metadata and, specifically, the level IDs are identical. The primary objective of this process is to ensure that the level IDs in the new schema are exactly equal to the level IDs in the old schema. Once complete, it is possible to switch to the new database, which can be done without recompiling application code.
Once the cross-check confirms that both schemas are exactly alike, a replication function of your choice (CPYF or custom replication tools) is used to copy the data from the original schema to the new schema. The time taken to transfer the data is purely a factor of the volume of data in the schema. Very large schemas can take a few days to replicate, depending on available resources.
Once the data has been copied across, the replication function should continue to check that the two schemas are in sync, ensuring that any changes made to the content of the original schema have been replicated immediately to the new schema.
Now you should set up a testing environment. The test uses the original application to test against the new schema while simultaneously running the original application. During this process, there should be no interruptions or changes to the original application.
The database architect can now maintain the new DDL schema and add constraints, keys, triggers, and anything else necessary to enhance the functionality of the new database and its associated dictionary. This will usually be an ongoing exercise, as you gradually start exploiting the incredible power of the SQL interface on DB2.
Cross-checking capabilities should be introduced in the background to continuously check that the structure of the schema and the structure as defined in the new database remain exactly alike. This helps to identify changes that may have been made to the schema's structure via a "backdoor," which could cause validation errors and data loss problems in the future.
Finally, the stage has been reached where the new schema has been completely tested, all cross-checks and data comparisons are complete, and everything is working to the user's satisfaction. The old DDS schema can now be phased out, and the original unchanged application can be switched over to the new DDL schema. The schema has been converted from DDS to DDL, and it has all been accomplished within a couple of days, with absolutely no application down time and no risk to business continuity.
And Other DBs In
Once you have your DB2 databases defined using DDL, with long table (file) names and long column (field) names enabled, your users will be presented with a modern-looking database, providing a solid foundation for you to use IBM i and DB2 as your consolidation platform.
For far too long, we have been guilty of cowering in the corner, allowing SQL Server and other tools to assume the incredible power we have in IBM i and DB2. The IBM i platform is significantly better-suited to be used as a consolidation platform, processing data from any other platform.
A variety of options exist here, and the most value can be unlocked by leveraging the inherent database processing capabilities of DB2 for i and RPG IV. A recent and powerful development in the form of ROA (Rational Open Access for RPG), allows you to develop a device handler for any non-DB2 database connection, accessing the contents of other non-DB2 databases as tables in RPG IV on IBM i. You can process and consolidate data, and produce reports and output from multiple sources. The potential of this approach is limitless, although it does require specialist programming skills.
Alternative tools, for example DB-GATE from RAZ-LEE, are available that allow access of non-DB2 data sources (SQL Server, Oracle, or any other SQL-compliant data source) on IBM i. This enables the access of specific files on DB2 and non-DB2 remote databases through natural interfaces such as interactive STRSQL or directly from any standard RPG, COBOL, and C programs.
This approach improves access by eliminating the need for SQLPKG on target DB2s. In addition, support for other databases is available:
- DB2
- Oracle
- Microsoft SQL Server
- Postgre SQL
- MySQL
- SQLite
- Firebird
- Excel CSV, TXT
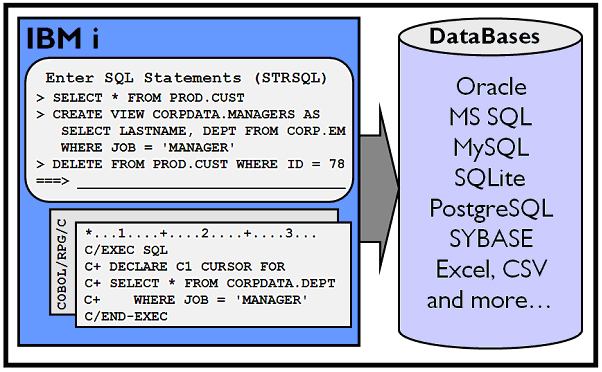
Figure 2: Get IBM i data into other databases.
We should recognize that improved performance and functional integration is possible across disparate systems, leveraging IBM i and DB2 capabilities. The IBM i platform is very well-suited to being the integration platform of choice, and using it is preferable to the conventional wisdom of years past: trying to extract data from DB2 on i to SQL Server or other databases to consolidate and then generating reports and other functions on languages inferior to RPG IV.
Thanks to Carol Hildebrandt
The author would like to thank Carol Hildebrandt for her contributions to this article. Carol has over 20 years of international marketing and sales experience, delivering enterprise-wide growth initiatives for IBM Storage & Technology Group, IBM Software Group, and other leading multinational IT brands. Carol was responsible for the launch of IBM PureSystems into emerging markets. She is the consulting Chief Marketing Officer for TEMBO Application Generation focusing on enterprise modernization on POWER Systems running IBM i, and is a contributing editor. LinkedIn profile: au.linkedin.com/in/carolhildebrandt/.

 Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new.
Business users want new applications now. Market and regulatory pressures require faster application updates and delivery into production. Your IBM i developers may be approaching retirement, and you see no sure way to fill their positions with experienced developers. In addition, you may be caught between maintaining your existing applications and the uncertainty of moving to something new. IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
IT managers hoping to find new IBM i talent are discovering that the pool of experienced RPG programmers and operators or administrators with intimate knowledge of the operating system and the applications that run on it is small. This begs the question: How will you manage the platform that supports such a big part of your business? This guide offers strategies and software suggestions to help you plan IT staffing and resources and smooth the transition after your AS/400 talent retires. Read on to learn:
LATEST COMMENTS
MC Press Online